Il metodo di lettura in ordine visto nella pagine precedente funziona perfettamente, ma non è efficiente. Il problema è il seguente: ogni volta che si legge un nuovo elemento da file, questo viene aggiunto in coda alla lista. L'operazione di aggiunta in coda, cosí come la abbiamo implementata, richiede la scansione di tutta la lista.
Supponiamo per esempio che il file da cui la lista va letta contiene 25 elementi. L'inserimento del primo non richiede scansione, dal momento che si tratta di inserire l'elemento nella lista vuota. D'altra parte, quando siamo arrivati, per esempio, al ventesimo elemento, per inserirlo in coda occorre prima fare la scansione di tutti i diciannove elementi precedentemente inseriti, solo per arrivare a conoscere l'indirizzo dell'ultima struttura della lista. Per inserire il ventunesimo occorre scandire da capo tutti i precedenti venti elementi che già stanno nella lista, ecc.
Supponiamo quindi di chiederci: quante operazioni vengono eseguite? Quando si inserisce l'i-esimo elemento vengono effettuate c × i operazioni, dove c è una costante (ossia: il numero di operazioni eseguite è proporzionale a i). Per inserire n elementi, occorre inserire il primo, poi il secondo, il terzo, ecc, quindi complessivamente servono:
costo inserimento costo inserimento ... primo elemento secondo elemento c × 1 + c × 2 + c × 3 + ... + c × n
Sfruttando una semplice regola algebrica, si può vedere come il valore di questa espressione sia proporzionale a n2. Quindi, per inserire n elementi abbiamo eseguito un numero quadratico di operazioni. Si noti che, al contrario, la costruzione della lista in ordine inverso (partendo cioè dall'ultimo elemento) richiedeva solo un numero lineare di operazioni. Questo è dovuto al fatto che l'elemento da inserire veniva messo in testa alla lista, per cui non era necessaria nessuna scansione: per ogni elemento da inserire si eseguivano un numero lineare di operazioni.
Vediamo ora un metodo di lettura della lista da file che richiede solo un numero lineare di operazioni. L'idea di base è la seguente: per aggiungere un elemento in coda a una lista occorre avere l'indirizzo dell'ultima struttura della lista; possiamo quindi memorizzare questo indirizzo in una variabile puntatore s, invece di fare ogni volta la scansione per arrivare all'ultima struttura. Occorre fare in modo che s punti sempre all'ultima struttura della lista anche dopo aver inserito un elemento in coda alla lista.
Mettiamo quindi un ciclo, in cui a ogni iterazione leggiamo un elemento e lo aggiungiamo in coda. L'aggiunta in coda si fa cosí: se la lista è vuota, allora coincide con l'aggiunta in testa; se la lista non è vuota, allora s punta all'ultima struttura, per cui si crea una nuova struttura il cui indirizzo viene messo in s->next (che prima conteneva, per definizione, NULL). In altre parole, si fa s->next=malloc(sizeof(struct NodoLista)). Sia che la lista fosse vuota oppure no, s deve alla fine puntare all'ultima struttura della nuova lista (questo è necessario per poter inserire il prossimo elemento). Se la lista era vuota, l'ultima struttura della nuova lista è la prima, per cui si può fare s=l. Se la lista non era vuota, s era il puntatore all'ultima struttura, che ora è la penultima. Per farlo puntare all'ultima, basta portare il puntatore avanti, con s=s->next.
A questo punto, s punta all'ultima struttura della lista. Possiamo quindi mettere il valore letto da file in s->val, e poi in s->next ci va il valore NULL che indica che la lista è finita.
Di seguito riportiamo la funzione main del programma leggivero.c che legge una lista da file in ordine.
int main (int argn, char *argv[]) {
FILE *fd;
int res;
int x;
TipoLista l, s;
/* controllo argomenti */
if( argn-1!=1 ) {
printf("Dare solo il nome del file come argomento\n");
exit(1);
}
/* apre il file */
fd=fopen(argv[1], "r");
if( fd==NULL ) {
perror("Errore in apertura del file");
exit(1);
}
/* inizializza la lista */
l=NULL;
while(1) {
/* tento di leggere un elemento */
res=fscanf(fd, "%d", &x);
if(res!=1)
break;
/* se ci riesco, creo una struttura */
if(l==NULL) { /* la lista era vuota */
l=malloc(sizeof(struct NodoLista));
s=l;
}
else { /* la lista contiene gia' elementi */
s->next=malloc(sizeof(struct NodoLista));
s=s->next;
}
/* ora s punta all'ultima struttura della lista */
s->val=x;
s->next=NULL;
}
/* chiude il file */
fclose(fd);
/* stampa la lista */
StampaLista(l);
return 0;
}
Proviamo ora a simulare l'evoluzione della memoria. Consideriamo la situazione in cui il file contiene solo i tre interi -77, 12, -34. All'inizio, l contiene il valore NULL, mentre s non è stato ancora assegnato (ha un valore indefinito).
Quando si legge il primo intero, viene creata una nuova struttura, il cui indirizzo viene messo in l, e viene poi copiato in s. A questo punto, si riempiono i campi val e next della struttura puntata da s.
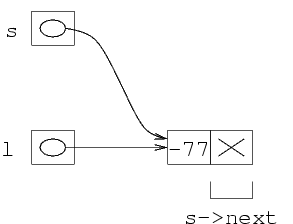
Si noti che s punta all'ultima struttura della lista (che è anche la prima, visto che la lista ha un solo elemento).
Dopo aver letto il secondo intero, si crea un nuova struttura, il cui indirizzo viene messo in s->next (la lista, a questo punto, non è vuota). Questo indirizzo va quindi a sovrascrivere il valore precedente, che era NULL. Si esegue poi la istruzione s=s->next, per cui s ora punta alla struttura che è appena stata creata. Si riempiono i campi val e next di questa struttura. Si noti che, alla fine della iterazione del ciclo, s contiene ancora l'indirizzo dell'ultima struttura della lista.
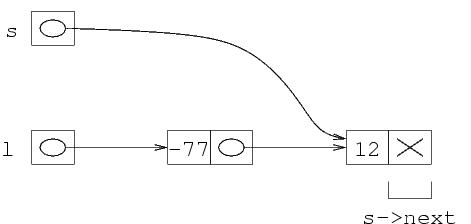
Si legge ora un altro elemento da file. Si crea una nuova struttura, il cui indirizzo va in s->next. Si porta ancora avanti il puntatore, per cui s punta all'ultima struttura della lista (quella appena creata), che viene riempita.
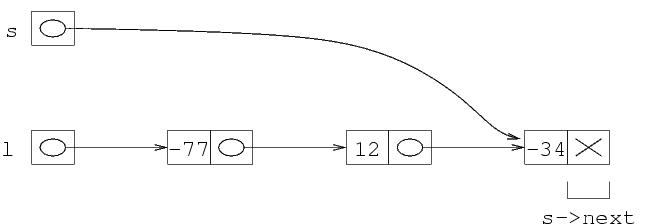
Il file, a questo punto è finito. Quando si esegue la istruzione fscanf, il valore di ritorno in res non vale 1, per cui si esce dal ciclo. A questo punto, la lista contiene già i valori letti da file, nell'ordine.
È importante notare che, alla fine di ogni iterazione del ciclo, la variabile s deve sempre puntare all'ultima struttura della lista: questo è necessario per poter poi inserire il prossimo elemento nella successiva iterazione del ciclo.