Vediamo degli algoritmi non banali:
Sono esempi di algoritmi
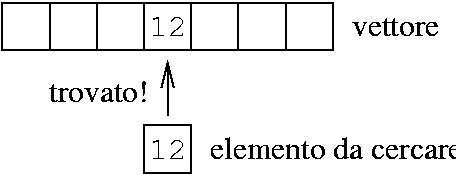
Problema: decidere se un intero si trova in un vettore
Soluzione: controllare ogni elemento.
public static boolean Cerca(int v[], int x) {
boolean trovato;
int i;
trovato=false;
for(i=0; i<v.length; i++)
if(v[i]==x)
trovato=true;
return trovato;
}
Quando ho trovato un elemento, il metodo continua ugualmente a verificare gli altri.
È un problema se:
Soluzione alternativa: quando trovo l'elemento, mi fermo.
public static boolean cerca(int v[], int x) {
int i;
for(i=0; i<v.length; i++)
if(v[i]==x)
return true;
return false;
}
Se l'elemento non c'è, finisco con il fare tutta la scansione del vettore.
In generale, questo è inevitabile.
Il vettore è ordinato se il primo elemento è minore del secondo, che è minore del terzo, ecc.
Vettori ordinati:
-1 0 3 10 60 120 900 -100 4 20 0 1 2 3 4 50
Vettori non ordinati:
-1 0 3 10 9 120 900 -100 4 20 0 1 0 1 2 3 4 50
Come si fa?
Posso usare gli stessi metodi dei vettori non ordinati.
Posso sfruttare l'ordinamento.
Domanda: che vantaggio ho?
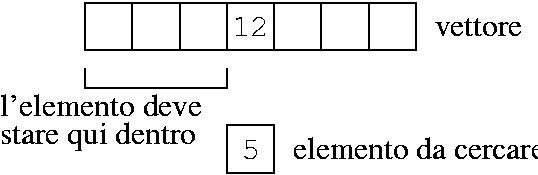
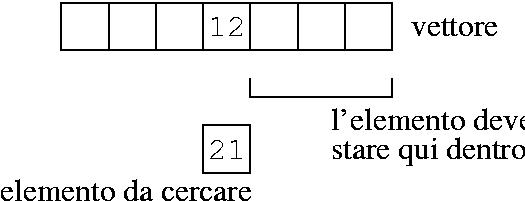
Se cerco 4, e trovo un elemento maggiore, so che è inutile andare avanti:
-2 -1 3 5 ...
Quando arrivo al 5, so che il 4 non lo trovo dopo, perchè altrimenti il vettore non sarebbe ordinato.
Esercizio: modificare il programma di ricerca per tenere conto di questo caso.
Dato un vettore v e un intero x, per ogni elemento del vettore:
Se si arriva alla fine, vuol dire che tutti gli elementi del vettore sono minori di x, e quindi si ritorna false
Si tratta solo di implementare l'algoritmo:
public static boolean cercaOrdinato(int v[], int x) {
int i;
for(i=0; i<v.length; i++) {
if(v[i]==x)
return true;
if(v[i]>x)
return false;
}
return false;
}
Trovare un vettore non ordinato su cui il metodo non funziona.
Se cerco 4 e trovo 5 mi fermo.
Se il vettore non è ordinato, il 4 può trovarsi dopo.
1 5 4
Si tratta ancora di trovare un elemento in un vettore ordinato.
Idea: invece di procedere sequenzialmente, parto da metà.
Tipo di ricerca ``elenco telefonico''
Parto da metà vettore
Se l'elemento è quello da cercare, ritorno true
Se l'elemento da cercare è minore di quello a metà del vettore, cerco nella prima metà
Se è maggiore, cerco nella seconda metà
Avrei solo due argomenti (il vettore e l'intero da cercare).
Metto altri due argomenti (indice di inizio e fine ricerca).
Algoritmo:
È un tipico algoritmo ricorsivo.
Trovare elemento in mezzo=divisione intera
Cercare nella prima metà=chiamata ricorsiva passando lo stesso indice di inizio e quello di mezzo meno uno.
Cercare nella seconda metà=...
Metodo ricorsivo senza i casi base:
public static boolean cercaBinario(int v[], int x, int inizio, int fine) {
...
int mezzo=(inizio+fine)/2;
if(v[mezzo]==x)
return true;
else if(v[mezzo]>x)
return cercaBinario(v, x, inizio, mezzo-1);
else
return cercaBinario(v, x, mezzo+1, fine);
}
Dove arrivo facendo le invocazioni ricorsive?
Prima o poi si arriva al caso: fine=inizio-1
Corrisponde alla ricerca in un vettore di zero elementi.
Si deve ritornare false
Traduco in codice anche il passo base.
public static boolean cercaBinario(int v[], int x, int inizio, int fine) {
if(inizio>fine)
return false;
int mezzo=(inizio+fine)/2;
if(v[mezzo]==x)
return true;
else if(v[mezzo]>x)
return cercaBinario(v, x, inizio, mezzo-1);
else
return cercaBinario(v, x, mezzo+1, fine);
}
Spazio di memoria/tempo che richiedono.
Devo tenere conto che:
Per la ricerca in vettore ordinato ho la ricerca sequenziale e la ricerca binaria.
L'efficienza dipende dal vettore e dall'elemento da cercare.
Caso in cui la ricerca sequenziale è più veloce:
v[]={1, 2, 3, 4, 5, 6, 7, 8, 9};
x=1;
Caso in cui la ricerca binaria è più veloce:
v[]={0, 3, 4, 10, 12, 143, 159, 200};
x=10;
Si danno valutazioni complessive:
In questo modo, posso dire quale algoritmo è il migliore complessivamente (senza specificare i dati di input).
Se il vettore ha quattro elementi, tutti gli algoritmi vanno bene.
L'efficienza è importante quando ci sono grandi quantità di dati (vettori grandi).
| pochi dati | poco tempo |
| tanti dati | tanto tempo |
Questa è una cosa naturale!
Assumo che ogni istruzione richiede tempo 1
Tempo di esecuzione=numero di istruzioni eseguite
Valutazione in base al numero dei dati
Ricerca sequenziale fino alla fine: tempo T(n)=n in ogni caso.
Ricerca sequenziale in cui mi fermo quando trovo: T(n)=n nel caso peggiore, T(n)=1 nel caso migliore.
Ricerca binaria: T(n)=log(n) nel caso peggiore, T(n)=1 nel caso migliore.
Perchè?
Il costo è log(n), se n è la dimensione del vettore
Dimostrazione ``al contrario'': se ci vogliono x operazioni, quanto è grande il vettore?
La ricerca richiede una operazione in più se il vettore è grande il doppio
Se la dimensione del vettore è esponenziale nel numero di operazioni, allora il numero di operazioni è logaritmico nella dimensione
Esempio: se ho 8 elementi alla prima invocazione riduco a 4, poi a 2 poi a 1, quindi servono 3 invocazioni. Se ho 16 elementi faccio 8, 4, 2, 1, ecc.
Assunzioni:
Per me, n2+3n+2 è come n2.
Non uso = perchè questo indica che due grandezze sono uguali
Uso una notazione diversa per dire ``è più o meno come'':
n2+3n+2=O(n2)
Si dice che la complessità è O(n2)
Caso che analizziamo noi: preso un vettore di interi metterli in ordine crescente.
Esempio: se ho il vettore che contiene:
9 4 3 8 1 5
Voglio il vettore che contiene gli stessi interi, ma in ordine:
1 3 4 5 8 9
Quindi, alla fine, v[0] deve essere minore di v[1] che deve minore di v[2], ecc
Noi vediamo solo come si ordina un vettore di interi, ma le stesse cose si possono fare con:
Nell'ultimo caso, deve essere possibile confrontare due oggetti (primo oggetto deve essere "minore" del secondo).
L'ordinamento < fra oggetti non c'è
Esempio di ordinamento: oggetti che contengono un intero, confronto in base agli interi (il primo oggetto deve contenere un intero minore di quello del secondo, ecc)
Trovo il primo e lo metto in prima posizione, trovo il secondo e lo metto in seconda posizione, ecc.
Vediamo prima come si mette il minimo in prima posizione.
Se il primo lo metto in prima posizione, cancello quello che c'era prima: v[0]=minimo cancella l'intero che prima stava in v[0].
Si perde il valore che prima stava in v[0]
Invece, io voglio che alla fine il vettore abbia tutti i valori che aveva all'inizio, ma in una sequenza diversa.
Soluzione: in v[0] ci metto il minimo, e il valore che stava prima in v[0] lo metto dove stava prima il minimo.
Si tratta di trovare il minimo in un vettore.
Dato che poi lo devo scambiare di posizione, devo anche sapere dove si trova.
Ricerca della posizione del minimo:
Se l'elemento più piccolo è v[minpos], allora lo devo mettere in v[0].
Se faccio v[0]=v[minpos], cancello il valore di v[0].
Trovo il valore di minpos tale che v[minpos] è l'elemento più piccolo del vettore.
L'intero che sta in v[minpos] lo metto in v[0] e viceversa.
public static void inPrima(int v[]) {
int i, minpos;
minpos=0;
for(i=0; i<v.length; i++)
if(v[i]<v[minpos])
minpos=i;
int temp=v[0];
v[0]=v[minpos];
v[minpos]=temp;
}
Nota: quando si passa un vettore a un metodo, questo equivale a copiare il suo indirizzo nella variabile locale (dato che è un oggetto).
Quando modifico il v locale, questo è lo stesso oggetto del vettore del programma principale.
La variabile del programma e la variabile del metodo sono due variabili diverse, ma contengono lo stesso indirizzo (le due freccie vanno verso lo stesso oggetto).
So come mettere il minimo in prima posizione.
Cosa resta da fare? Ordinare il resto del vettore.
Tipico esempio di metodo ricorsivo:
ordina il vettore=metti il minimo all'inizio+ordina il resto del vettore
Ricorsione sui vettori: serve un vettore senza il primo
Invece di creare un nuovo vettore, aggiungo dei parametri al metodo
Alla prima invocazione, devo ordinare tutto il vettore, alla seconda tutto tranne il primo, poi tutto tranne il secondo, ecc.
Aggiungo un parametro inizio:
public static void ordina(int v[], int inizio) { ... }
Ordina il vettore a partire dall'indice inizio fino alla fine.
Ossia: ordina la parte di vettore v[inizio], v[inizio+1], ... , v[v.length-1]
Metto il minimo in prima posizione, poi ordino quello che resta del vettore.
Non va fatto su tutto il vettore, ma solo da inizio alla fine!
Faccio la chiamata ricorsiva passando inizio+1
Implementazione dell'algoritmo:
public static void ordina(int v[], int inizio) {
int i, minpos;
minpos=inizio;
for(i=inizio; i<v.length; i++)
if(v[i]<v[minpos])
minpos=i;
int temp=v[inizio];
v[inizio]=v[minpos];
v[minpos]=temp;
ordina(v, inizio+1);
}
Faccio tutto sul vettore da inizio in poi, invece che su tutto il vettore (da 0 in poi)
Quindi, metto inizio dove prima c'era 0
Cosa manca?
Manca il caso base.
Ogni volta che invoco il metodo, la parte di vettore da guardare ha un elemento in meno.
Alla fine, arrivo al vettore di un elemento
Questo succede quando inizio è l'ultimo elemento del vettore.
Il vettore di un elemento è già ordinato.
In altre parole: inizio aumenta di uno a ogni invocazione ricorsiva. Quando arriva alla fine, devo ordinare la parte di vettore con un elemento solo (un vettore di uno o zero elementi è sempre in ordine)
public static void ordina(int v[], int inizio) {
int i, minpos;
if(inizio>=v.length-1)
return;
minpos=inizio;
for(i=inizio; i<v.length; i++)
if(v[i]<v[minpos])
minpos=i;
int temp=v[inizio];
v[inizio]=v[minpos];
v[minpos]=temp;
ordina(v, inizio+1);
}
Questo algoritmo di ordinamento si chiama selectionsort
Ricorsione ---> iterazione
Se la chiamata ricorsiva sta alla fine, è facile.
In questo caso, ripeto tutta la parte:
minpos=inizio;
for(i=inizio; i<v.length; i++)
if(v[i]<v[minpos])
minpos=i;
int temp=v[inizio];
v[inizio]=v[minpos];
v[minpos]=temp;
Questa parte viene eseguita prima con inizio=0, poi con inizio=1, poi con inizio=2.
L'ultima volta che si esegue questa parte, inizio vale v.length-2: infatti, quando si fa la invocazione passando v.length-1, il metodo termina subito, prima di eseguire la ricerca del minimo.
Faccio un ciclo in cui inizio va da 0 a v.length-2.
public static void ordina(int v[]) {
int i, minpos, inizio;
for(inizio=0; inizio<=v.length-2; inizio++) {
minpos=inizio;
for(i=inizio; i<v.length; i++)
if(v[i]<v[minpos])
minpos=i;
int temp=v[inizio];
v[inizio]=v[minpos];
v[minpos]=temp;
}
}
Quante operazioni vengono eseguite?
Considero un vettore di n elementi, senza specificare quali valori contiene.
Alla prima chiamata ricorsiva, faccio n iterazioni.
Alla seconda, faccio n-1 iterazioni, ecc.
Totale: n+(n-1)+(n-2)+...+2+1 = n(n+1)/2
Ignoro le costanti e i termini inferiori: viene n2, quindi dico che la complessità è O(n2)
La complessità si valuta facilmente sulla versione iterativa:
Il ciclo esterno ha n iterazioni.
Il ciclo interno ha un numero di iterazioni da n a 1, di media n/2
L'istruzione dentro il ciclo interno viene eseguita n.n/2 volte
Metodo dell'istruzione dominante: vado a vedere quante volte si esegue l'istruzione dentro i cicli maggiormente nidificati.
Vengono eseguite O(n2) operazioni indipendentemente dai valori scritti nel vettore.
La complessità del caso migliore e peggiore coincidono: sono tutte e due O(n2)
Vantaggio: più efficiente nel caso migliore.
Alla fine, l'elemento maggiore sta per forza nell'ultima posizione.
Infatti: quando arrivo all'elemento massimo, lo scambio con il successivo. A questo punto, confronto il successivo (che è ancora il massimo) con quello dopo, ecc:
1 10 3 2 4 5
Quando confronto 10 con 3, li scambio:
1 3 10 2 4 5
Ora il confronto è fra 10 e 2:
1 3 2 10 4 5
Il primo elemento del confronto è ancora il massimo
Il massimo elemento, essendo maggiore di tutti gli altri, non può venire ``fermato'' nel suo percorso verso la fine del vettore
Ripeto il confronto, con eventuale scambio, fra 0,1 fino a v.length-2, v.length-1
Nota: quando ci sono cicli con vettori, controllare gli indici dei vettori nella prima e nell'ultima iterazione:
Nel primo caso, certe operazioni da fare non vengono fatte; nel secondo caso, si genera un errore in esecuzione ArrayOutOfBound
Faccio un ciclo da 0 a v.length-2, ogni volta confronto ed eventualmente scambio un elemento con il successivo.
public static void maxDopo(int v[]) {
int i, temp;
for(i=0; i<=v.length-2; i++)
if(v[i]>v[i+1]) {
temp=v[i];
v[i]=v[i+1];
v[i+1]=temp;
}
}
Se v[i]<=v[i+1] allora li lascio in pace, altrimenti li scambio.
Quindi, se v[i]>v[i+1] li scambio, altrimenti non faccio niente.
Per lo scambio, serve sempre la variabile temporanea.
Quando eseguo il ciclo, il massimo "risale" fino alla cima del vettore.
Dopo aver fatto questo, resta da ordinare il resto del vettore (tutto tranne l'ultimo elemento).
Versione ricorsiva: invece di copiare il vettore, specifico dove il vettore termina (dove finisce la parte di vettore da ordinare)
public static void ordina(int v[], int fine) { ... }
Questo metodo ordina la parte di vettore da 0 a fine
Faccio il ciclo di confronti, che mette il massimo alla fine.
Faccio la invocazione ricorsiva su tutto il vettore tranne il primo elemento.
public static void ordina(int v[], int fine) {
int i, temp;
for(i=0; i<=fine-1; i++)
if(v[i]>v[i+1]) {
temp=v[i];
v[i]=v[i+1];
v[i+1]=temp;
}
ordina(v, fine-1);
}
Cosa manca?
La parte di vettore da ordinare diventa sempre più piccola a ogni invocazione ricorsiva.
In altre parole: alla prima invocazione fine vale v.length-1 poi diminusce di uno, poi di uno, ecc.
Quando fine==0 la parte di vettore da ordinare è il solo primo elemento.
Un vettore (o una parte di vettore) fatta di un solo elemento è già ordinata.
public static void ordina(int v[], int fine) {
int i, temp;
if(fine==0)
return;
for(i=0; i<=fine-1; i++)
if(v[i]>v[i+1]) {
temp=v[i];
v[i]=v[i+1];
v[i+1]=temp;
}
ordina(v, fine-1);
}
Questa parte viene ripetuta:
for(i=0; i<=fine-1; i++)
if(v[i]>v[i+1]) {
temp=v[i];
v[i]=v[i+1];
v[i+1]=temp;
}
La prima volta con fine pari a v.length-1, poi con v.length-2, ecc, fino a 1 (quando fine vale 0 questa parte non viene eseguita, perchè viene fatto subito return)
Faccio un ciclo con fine che va da v.length-1 a 1.
public static void ordina(int v[]) {
int i, temp, fine;
for(fine=v.length-1; fine>=1; fine--) {
for(i=0; i<=fine-1; i++)
if(v[i]>v[i+1]) {
temp=v[i];
v[i]=v[i+1];
v[i+1]=temp;
}
}
}
Vettore grande n, di cui non specifico i valori.
Il ciclo esterno ha n iterazioni.
Il ciclo interno ha n iterazioni la prima volta, poi n-1, ecc: di media, ho n/2 iterazioni.
Totale: O(n2)
Questo vale sia nel caso migliore che nel caso peggiore.
Se faccio tutto il ciclo interno senza mai fare scambi, vuol dire che il vettore è ordinato.
Infatti, ho:
for(i=0; i<=fine-1; i++)
if(v[i]>v[i+1])
scambia
Se non scambio, vuol dire che v[i]<v[i+1] su tutto il vettore.
In questo caso, non serve fare le iterazioni successive (il vettore è già ordinato)
Prima di iniziare ogni catena di scambi, assumo che il vettore sia ordinato.
Se scambio degli elementi, allora non lo era.
Se alla fine non ho fatto scambi, termino senza andare avanti.
boolean ordinato=true;
for(i=0; i<=fine-1; i++)
if(v[i]>v[i+1]) {
ordinato=false;
scambia
}
if(ordinato)
return;
Come al solito, if(ordinato) è lo stesso di if(ordinato==true).
Nota: ordinato indica se il vettore era già ordinato prima di fare i confronti.
Uguale a prima, ma ci metto anche la verifica.
public static void ordina(int v[]) {
int i, temp, fine;
for(fine=v.length-1; fine>=1; fine--) {
boolean ordinato=true;
for(i=0; i<=fine-1; i++)
if(v[i]>v[i+1]) {
ordinato=false;
temp=v[i];
v[i]=v[i+1];
v[i+1]=temp;
}
if(ordinato)
return;
}
}
Caso peggiore: devo fare tutto come prima, quindi ho O(n2)
Caso migliore: il vettore è già ordinato
In questo caso, faccio una intera catena di confronti (eseguo una volta tutto il ciclo più interno), mi accorgo che trovato vale true, e termino.
Costo di caso migliore: O(n)
Il nuovo metodo ha la stessa complessità nel caso peggiore, ma minore nel caso migliore.
Nessun metodo di ordinamento può avere complessità minore di O(n)
Infatti, devo almeno verificare se il vettore è già ordinato.
Quindi, il BubbleSort è ha complessità ottima nel caso migliore.
Esistono algoritmi di ordinamento che impiegano O(n log n) nel caso peggiore.
Quindi: il BubbleSort è ottimo nel caso migliore, ma non nel caso medio.
Basato sul fatto che si possono fondere (merge) due array ordinati in un unico array ordinato in tempo lineare
Algoritmo:
Tengo un indice sul primo e sul secondo vettore
A ogni passo, scelgo il più piccolo, e lo metto nel vettore nuovo
public static int[] merge(int v[], int w[]) {
int nuovo[]=new int[v.length+w.length];
int i, j, z;
i=0;
j=0;
for(z=0; z<v.length+w.length; z++) {
if(v[i]<w[j]) {
nuovo[z]=v[i];
i++;
}
else {
nuovo[z]=w[j];
j++;
}
}
return nuovo;
}
Come funziona?
Situazione iniziale:
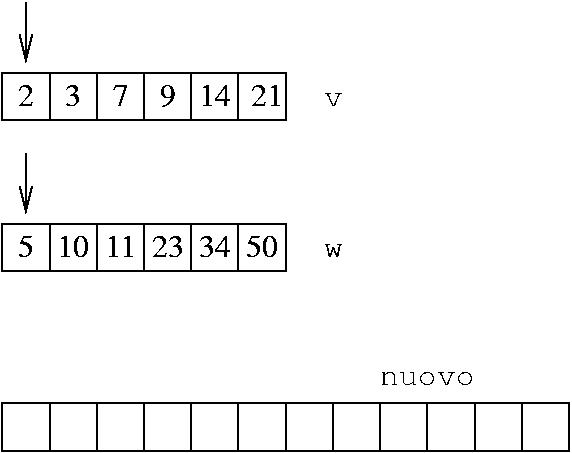
Uso due freccie per indicare i valori di i e j
Dato che v[i]<v[j], metto v[i] nel vettore nuovo, e incremento i
Lascio bianca la prima posizione del primo
vettore per chiarezza
(dentro c'è ovviamente
ancora il valore 5)
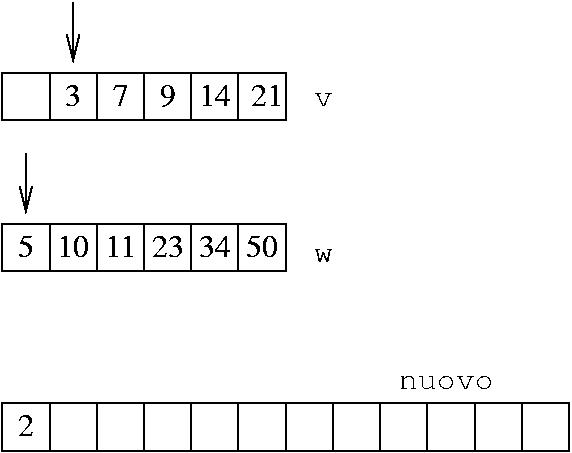
Il più piccolo fra i due elementi puntati dalle freccie è quello di v: lo copio nel vettore nuovo
Situazione attuale:
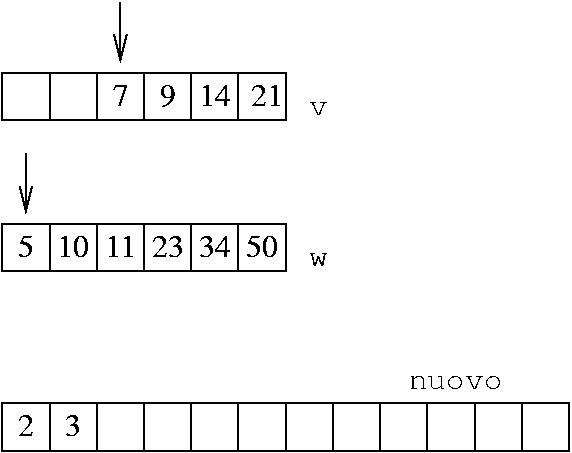
Questa volta è w[j] quello più piccolo: lo copio nel vettore nuovo

Questa volta è di nuovo l'elemento di v quello più piccolo
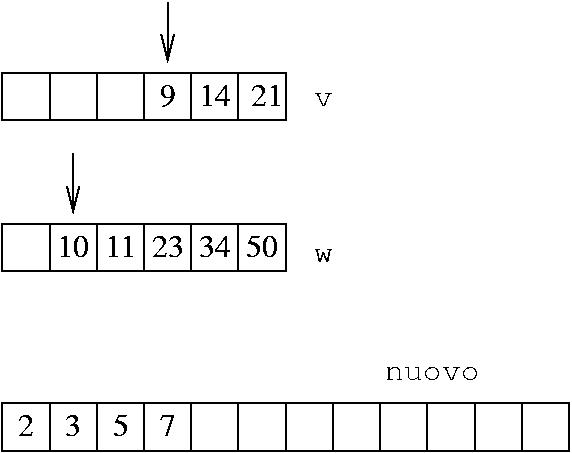
Vado avanti fino alla fine
Ad ogni passo, il vettore nuovo contiene un elemento in più
Ad ogni passo, l'elemento che viene messo nel vettore nuovo è:
Quindi, ad ogni passo viene sempre messo nel vettore nuovo l'elemento più piccolo fra quelli che mancano
Il programma di sopra funziona solo finchè i vettori non sono finiti
Andando avanti, si arriva a questo punto:
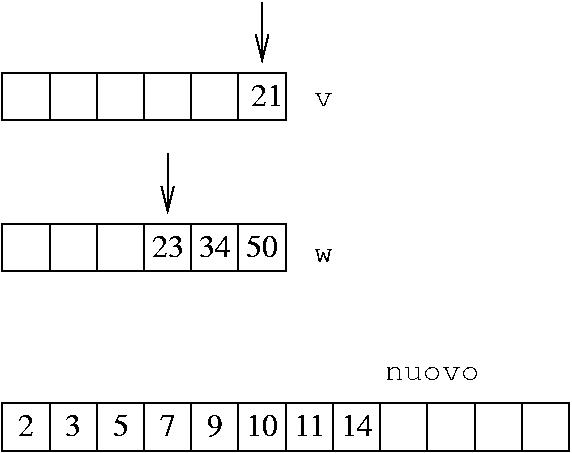
L'elemento di v è più piccolo per cui viene copiato
Ora l'indice su v viene ancora incrementato, per cui va fuori:
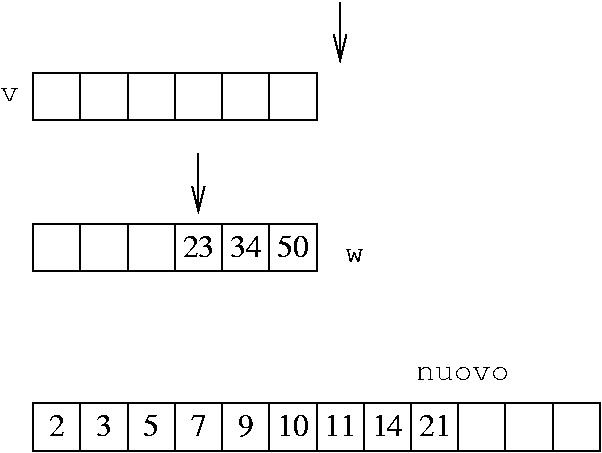
Quando si va a fare il confronto fra v[i] e v[j], si genera un errore
Il problema è che i è troppo grande (non è un indice valido per l'array)
Modifico il codice: quando uno degli indici è fuori dal vettore, copio l'elemento dell'altro
Algoritmo: prendo sempre l'elemento più piccolo fra i due vettori e passo all'elemento successivo di quel vettore; quando non ci sono più elementi di uno dei due vettori, copio sempre l'altro
public static int[] merge(int v[], int w[]) {
int nuovo[]=new int[v.length+w.length];
int i, j, z;
i=0;
j=0;
for(z=0; z<v.length+w.length; z++) {
if(j>=w.length) {
nuovo[z]=v[i];
i++;
}
else if(i>=v.length) {
nuovo[z]=w[j];
j++;
}
else if(v[i]<w[j]) {
nuovo[z]=v[i];
i++;
}
else {
nuovo[z]=w[j];
j++;
}
}
return nuovo;
}
Quante operazioni servono per eseguire il metodo di merge?
La parte principale del metodo è dentro un ciclo:
for(z=0; z<v.length+w.length; z++) {
...
}
All'interno del ciclo ho solo un numero costante di operazioni (al più, 6 operazioni
Il numero di operazioni è quindi proporzionale a v.length+w.length
Costo di esecuzione: O(n) dove n è la dimensione complessiva dei due vettori
È un algoritmo ricorsivo
int [] mergeSort(int v[]) {
...
}
Per semplicità, realizziamo un metodo che ritorno un altro vettore (ordinato), invece di ordinare quello passato come parametro
Supponiamo che sia la prima metà che la seconda metà del vettore siano già ordinate:

Per ottenere un unico vettore ordinato, potrei usare il metodo di fusione
Creo due vettori in cui copio le due parti, e poi faccio la fusione di vettori ordinati:
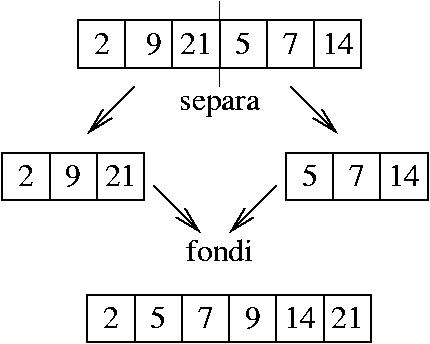
Questo metodo funziona soltanto se le due metà del vettore sono già ordinate
Se non lo sono?
Le devo ordinare
Il metodo mergeSort(v) fa esattamente questo: ordina un vettore.
I due vettori più piccoli li posso ordinare con due invocazioni ricorsive
Se il vettore è grande 0 oppure 1 elemento, restituisco un vettore uguale
Non dovete ricordare a memoria il metodo
L'algoritmo invece sí
public static int[] mergeSort(int v[]) {
int ordinato[]=new int[v.length];
if(v.length==0)
return ordinato;
if(v.length==1) {
ordinato[0]=v[0];
return ordinato;
}
int primo[]=new int[v.length/2];
int secondo[]=new int[(v.length+1)/2];
System.arraycopy(v, 0, primo, 0, v.length/2);
System.arraycopy(v, v.length/2, secondo, 0, (v.length+1)/2);
int primo_ord[]=mergeSort(primo);
int secondo_ord[]=mergeSort(secondo);
return merge(primo_ord, secondo_ord);
}
Perchè ho v.length/2 da una parte e (v.length+1)/2 dall'altra?
Se il vettore ha un numero dispari di elementi, allora facendo due parti grandi v.length/2 mi perdo l'ultimo elemento
A ogni passo, ho un costo lineare (escludendo il costo delle invocazioni ricorsive)
Perè il costo è lineare nella dimensione del vettore passato, non in quella del vettore originario
In altre parole: anche se il vettore di partenza è grande 100, a un certo punto farò le invocazioni ricorsive con vettori grandi 10
Il problema si risolve osservando la sequenza delle invocazioni ricorsive
Le prime due invocazioni sono fatte su vettori grandi la metà:
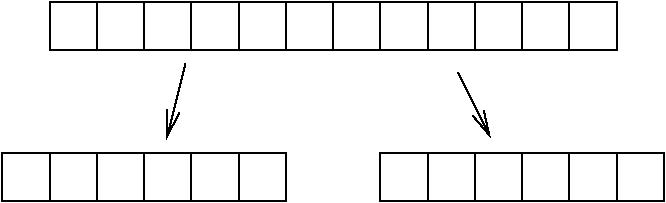
Ognuna delle due invocazioni ne fa altre due, su vettori grandi ancora la metà:
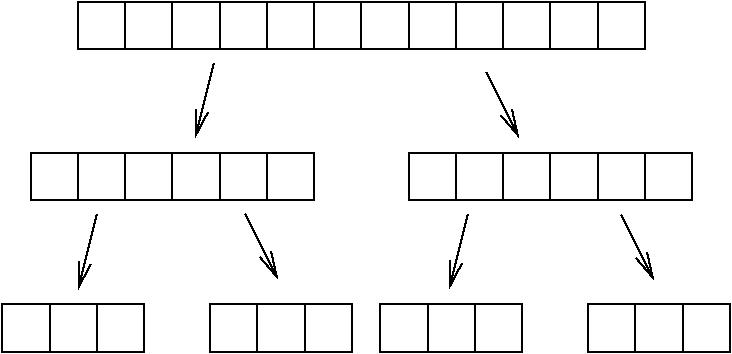
In ogni chiamata ricorsiva, il vettore viene ancora spezzato e vengono fatte due invocazioni:

ecc.
Contare le caselline di ogni riga
In ogni riga, ho sempre un numero di caselle uguale alla dimensione del vettore di partenza
Quindi?
Ogni sottovettore corrisponde a una invocazione ricorsiva
Ogni invocazione ricorsiva ha costo pari alla dimensione del vettore passato
Quindi, il totale di tutte le invocazioni ricorsive che corrispondono a una certa riga ha costo n (dimensione del vettore originario)
Ogni riga ha costo n
Ci sono log(n) righe.
Costo totale del mergesort: O(n log(n))
Si può dimostrare che non esistono algoritmi più efficienti