Sia l il puntatore iniziale a una lista di elementi interi, già costruita in memoria con strutture e puntatori. Scrivere una funzione che modifichi la lista nel modo seguente:
La funzione deve rilasciare tutta la memoria dinamica eventualmente non più utilizzata nella lista modificata.
Ad esempio, ricevendo in ingresso la lista seguente (con un numero dispari di elementi)
(4 -4 12 6 -22)
La funzione deve restituire in uscita la seguente lista modificata:
(0 18)
Si noti che l'ultimo elemento è stato correttamente eliminato.
ATTENZIONE: la funzione non deve creare una nuova lista, ma modificare la lista già esistente in memoria.
Il programma driver, in cui va inserita la funzione che risolve il problema, è 26-6-2000-driver.c Il programma legge la lista da file, e il nome di questo file va specificato come argomento del programma.
Risolviamo il problema usando quattro possibili metodi: abbiamo quindi una soluzione ricorsiva e tre soluzioni iterative. In particolare, le soluzioni iterative sono: una soluzione basata sulla progettazione top-down e bottom-up; una soluzione iterativa realizzata con una sola funzione; una soluzione iterativa con uso di un record generatore.
Partiamo dai casi base: se la lista è vuota, non si deve fare niente (non ci sono elementi da eliminare oppure da accorpare). Se la lista ha un solo elemento, allora va eliminato (è un elemento dispari). Se la lista ha due elementi, allora si mette nel primo la somma dei due valori, e si elimina il secondo.
Il terzo caso è quello più interessante. Infatti, dopo aver eliminato il secondo elemento, quello che occorre fare è ripetere la stessa procedura sul resto della lista. Infatti, accorpare il primo e il secondo elemento del resto della lista equivale ad accorpare il terzo e il quarto della lista originale, ecc. Si vede chiaramente che la cosa funziona anche nel caso in cui la lista ha un elemento dispari di elementi: in questo caso, l'ultima chiamata ricorsiva viene fatta su una lista composta da un unico elemento, che viene quindi eliminato (vedi il caso base di sopra).
La funzione complessiva viene riportata qui sotto.
void AccorpaRicorsiva(TipoLista *pl) {
TipoLista s;
/* caso di lista vuota */
if(*pl==NULL)
return;
/* lista di un solo elemento */
if((*pl)->next==NULL) {
free(*pl);
*pl=NULL;
return;
}
/* accorpa primo e secondo */
(*pl)->val=(*pl)->val+(*pl)->next->val;
/* libera il secondo */
s=(*pl)->next->next;
free((*pl)->next);
(*pl)->next=s;
/* chiamata ricorsiva */
AccorpaRicorsiva(&(*pl)->next);
}
Risolviamo il problema in modo iterativo. Da una semplice analisi del problema si intuisce che la eliminazione dell'ultimo elemento (se dispari) e l'accorpamento delle coppie sono due problemi differenti. Infatti, mentre per accorpare una coppia basta l'indirizzo della prima struttura (infatti, qui mettiamo la somma, e poi eliminiamo il successivo elemento), per eliminare l'ultimo elemento serve l'indirizzo della struttura precedente. La soluzione che viene proposta subito dopo questa è basata su una unica funzione iterativa, e si vede che è piuttosto complicata, dato il numero di casi da tenere in considerazione.
Tentiamo invece di risolvere il problema in modo top-down, usando anche il meccanismo bottom-up di usare funzioni che già sappiamo scrivere.
Nel nostro caso, il problema si può scrivere in modo algoritmico, ad alto livello, nel modo seguente:
if( la lista ha un numero dispari di elementi ) elimina ultimo elemento della lista; accorpa gli elementi a coppie
Questo algoritmo contiene tre frasi scritte in italiano, che occorre tradurre in altrettanti frammenti di codice C. In particolare, se un frammento di codice realizza una funzionalità ben definita, è bene realizzarlo usando una funzione separata. Scrivere il codice usando funzioni separate, in modo tale che ogni funzione fa una cosa facilmente definibile è un vantaggio, perchè rende il codice facile da scrivere e da capire, permette il testing modulare del programma, e aumenta la probabilità che il codice sia corretto.
In questo caso, dovremmo scrivere tre funzioni, che fanno queste tre cose:
La seconda cosa da fare corrisponde a una funzione già vista, e quindi non crea nessun problema. Per quello che riguarda il controllo sul numero di elementi, notiamo che in effetti abbiamo già scritto una funzione che conta il numero di elementi di una lista. È quindi conveniente usare questa funzione piuttosto che scriverne una nuova. Per quello che riguarda la funzione di accorpamento, questa va scritta ex-novo. La funzione principale è fatta come segue.
void AccorpaTopDown(TipoLista *pl) {
if(ContaElementi(*pl)%2==1)
EliminaCodaLista(pl);
AccorpaPaia(*pl);
}
Non si riportano qui le funzioni di conteggio elementi e di eliminazione dell'ultimo, perchè già visti in altre pagine, e comunque di facile realizzazione.
Quello che manca è solo la funzione di accorpamento. Notiamo che, per come questa funzione viene chiamata, si ha la garanzia che la lista è composta da un numero pari di elementi: infatti, anche se la lista avesse avuto un numero dispari di elementi, l'ultimo sarebbe stato già eliminato.
Possiamo procedere in questo modo: per ogni elemento della lista, sommiamo ad esso il successivo, e poi eliminiamo il successivo. A questo punto, andiamo avanti con la scansione. L'algoritmo si può quindi scrivere come segue:
while( ci sono ancora elementi ) {
somma il primo elemento con il secondo
elimina il secondo
passa all'elemento successivo
}
Si tratta quindi di una scansione. A ogni passo, si somma l'elemento scandito con il sucessivo. Si elimina poi il successivo. A questo punto, si deve ripetere sul terzo elemento della lista originale, che ora è il secondo (dato che il secondo originale è stato eliminato). Dato che la lista contiene sicuramente un numero pari di elementi, se la lista contiene un elemento allora ne contiene due. Quindi, se la lista contiene ancora un elemento, allora va accorpato con il successivo. Tutto questo ci dice che si può uscire dal ciclo solo quando siamo arrivati alla fine della lista, ossia la lista puntata dal puntatore di scansione è vuota.
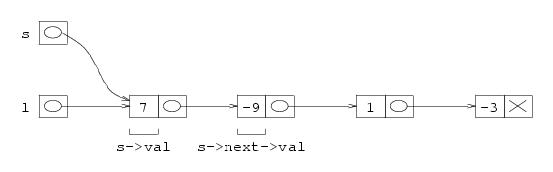
Vediamo un esempio di lista, e proviamo a scrivere il codice che corrisponde all'algoritmo di sopra. Per prima cosa, usiamo una variabile s per fare la scansione, per cui la prima istruzione sarà s=l, dove l è l'indirizzo iniziale della lista.
La prima cosa da fare è sommare il secondo elemento al primo. Questo si realizza facendo semplicemente s->val = s->val + s->next->val. Nell'esempio, si sommano 7 e -9, ottenendo -2, che viene messo al posto del 7.

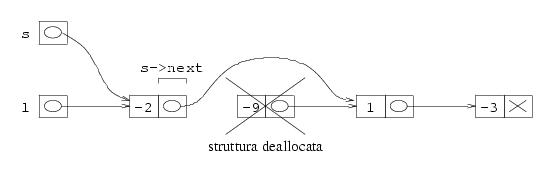
A questo punto, si elimina il secondo elemento della lista. Anche questo è facile: si tratta di modificare s->next, che deve diventare uguale a s->next->next. Dato che la seconda struttura va dellocata, occorre memorizzare il suo indirizzo (che inizialmente si trova in s->next) in una variabile temporanea. Il codice che realizza questa eliminazione è il seguente:
t=s->next; s->next=s->next->next; free(t);
La situazione della memoria dopo l'esecuzione di queste tre istruzioni è la seguente:
A questo punto, occorre ripetere le due fasi di somma ed eliminazione sul terzo e quarto elemento della lista. Si tratta quindi di ripetere le stesse istruzioni, ma prima occorre spostare s sul terzo elemento della lista. Si noti che il terzo elemento della lista originaria è ora il secondo (dato che abbiamo fatto l'eliminazione). Per spostare s in modo che punti al terzo elemento della lista originaria, basta fare s=s->next una sola volta, e si ottiene la situazione seguente:
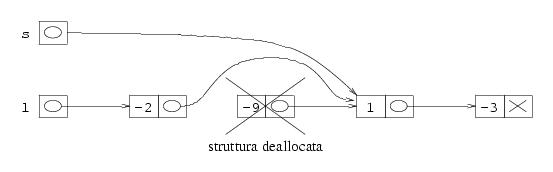
A questo punto, possiamo ripetere le stesse istruzioni. È quindi chiaro che occorre fare un ciclo. Va specificata la condizione di uscita dal ciclo. Si noti che, nella figura di sopra, s->next->next vale NULL, ma il corpo del ciclo va eseguito ancora una volta. Dopo averlo eseguito, abbiamo finito l'accorpamento, e quindi si può uscire dal ciclo. Si vede facilmente che, dopo aver eseguito il corpo del ciclo ancora una volta, la variabile s vale NULL. La condizione di uscita dal ciclo è quindi s!=NULL, che fa uscire dal ciclo quando s vale NULL.
Si noti che il puntatore alla prima struttura della lista non viene mai modificato, per cui la lista si può passare per valore (e si può anche usare l come variabile di scansione). La funzione di accorpamento si può quindi realizzare come segue.
void AccorpaPaia(TipoLista l) {
TipoLista s, t;
s=l;
while(s!=NULL) {
s->val=s->val+s->next->val;
t=s->next;
s->next=s->next->next;
free(t);
s=s->next;
}
}
Rispetto alla soluzione iterativa con una sola funzione riportata qui sotto, questa soluzione presenta almeno due vantaggi:
Rispetto alle soluzioni ricorsive e iterativa con una sola funzione, può sembrare che la soluzione con tre funzioni ausiliarie presenti un problema di efficienza. Infatti, mentre le altre due soluzioni fanno una sola scansione della lista, questa ne fa (nel caso peggiore) tre: una per contare gli elementi, una per eliminare l'ultimo elemento, una per accorpare gli elementi. D'altra parte, il costo di ogni scansione è lineare nella lunghezza della lista, dato che su ogni elemento si fanno un numero costante di operazioni. Questo significa che la soluzione con tre scansioni richiede tempo 3 * c n, dove c è una costante e n il numero di elementi della lista. Quindi, l'intera funzione è lineare esattamente come le altre due: tutte e tre le funzioni sono O(n).
Riassumendo, fare tre volte la scansione di una lista non rappresenta un peggioramento di efficienza, dato che si sta moltiplicando per tre il costo di scansione, e le costanti moltiplicative si ignorano quando si fanno valutazioni di efficienza.
Chi ha deciso di farsi del male può provare a risolvere il problema con una singola funzione che lavora in modo iterativo. La eliminazione degli elementi pari da una lista non presenta grandi difficoltà: si tratta di prendere un elemento, eliminare il successivo, e poi passare al nuovo elemento successivo.
Nel nostro caso, il problema è complicato dal fatto che potremmo arrivare a un elemento della lista che non ha un successore. In questo caso, l'elemento è l'ultimo della lista, e non ha un successore con cui essere accorpato, per cui va cancellato. Serve quindi sapere l'indirizzo della struttura che lo precede.
Abbiamo quindi questa situazione: di solito, ci serve l'indirizzo della struttura di posizione pari, ma alla fine può essere necessario sapere l'indirizzo della struttura precedente. Quindi, dobbiamo sempre sapere l'indirizzo della struttura precedente. Questo fa sí che la funzione debba tenere conto separatamente dei casi in cui la lista ha zero, uno o due elementi. Il ciclo può iniziare solo dopo che il secondo elemento è stato eliminato, per cui ho l'indirizzo della prima struttura, che ora è seguita dalla terza.
void AccorpaIterativa(TipoLista *pl) {
TipoLista s, t;
/* caso di lista vuota */
if(*pl==NULL)
return;
/* lista di un solo elemento */
if((*pl)->next==NULL) {
free(*pl);
*pl=NULL;
return;
}
/* accorpa primo e secondo */
(*pl)->val=(*pl)->val+(*pl)->next->val;
/* libera il secondo */
s=(*pl)->next->next;
free((*pl)->next);
(*pl)->next=s;
/* ciclo sui successivi */
s=*pl;
while(s->next!=NULL) {
/* ho solo un elemento davanti */
if(s->next->next==NULL) {
free(s->next);
s->next=NULL;
return;
}
/* ho due elementi davanti */
s=s->next;
s->val=s->val+s->next->val;
t=s->next->next;
free(s->next);
s->next=t;
}
}
Come si vede, il codice finale è piuttosto complesso. Questo può facilmente portare a degli errori di programmazione. In questo caso, la soluzione ricorsiva è migliore.
Una alternativa a questa soluzione è quella di contare gli elementi della lista con una prima scansione, eliminare l'ultimo se il numero degli elementi è dispari, e poi procedere all'accorpamento degli elementi a coppie. Questo richiede la scansione multipla della lista. Un'altra alternativa possibile è quella di fare prima l'accorpamento, contando nel contempo il numero di elementi della lista: se questo numero è dispari, si fa poi l'eliminazione dell'ultimo elemento (questo richiede comunque la doppia scansione della lista).
La funzione di sopra si può semplificare mediante l'uso dell'elemento generatore. Si parte mettendo un elemento in testa alla lista. Questo ci permette di risparmiare l'accorpamento del primo e secondo elemento, dato che questo viene poi fatto all'interno del ciclo (infatti, il primo e il secondo elemento sono ora diventati il secondo e il terzo, grazie all'elemento generatore).
void AccorpaGeneratore(TipoLista *pl) {
TipoLista s, t;
/* crea il record generatore */
s=*pl;
*pl=malloc(sizeof(struct NodoLista));
(*pl)->next=s;
/* ciclo sui successivi */
s=*pl;
while(s->next!=NULL) {
/* ho solo un elemento davanti */
if(s->next->next==NULL) {
free(s->next);
s->next=NULL;
break; /* attenzione: non return! */
}
/* ho due elementi davanti */
s=s->next;
s->val=s->val+s->next->val;
t=s->next->next;
free(s->next);
s->next=t;
}
/* elimina il record generatore */
s=*pl;
*pl=(*pl)->next;
free(s);
}
In questo caso, occorre prestare attenzione al fatto che ogni punto di uscita della funzione deve contenere l'eliminazione dell'elemento generatore. Non possiamo quindi mettere return in mezzo al ciclo (come veniva fatto nella soluzione precedente) senza aver prima eliminato l'elemento generatore. Il break fa saltare fuori da ciclo, per cui viene eseguita l'eliminazione.