I compiti di esame scritti contengono un esercizio di programmazione e due domande. Di seguito viene data solo la soluzione della parte di programmazione.
Sia A il puntatore alla radice di un albero binario, i cui nodi contengono valori interi, già presente in memoria. Scrivere una funzione C che, ricevendo come argomento A, calcoli la somma S1 dei valori contenuti nei nodi del sottoalbero sinistro; quindi calcoli la somma S2 dei valori contenuti nei nodi del sottoalbero destro, e restituisca la differenza S1-S2.
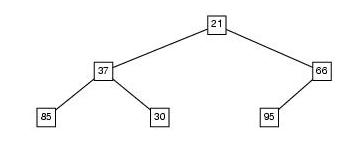
Per esempio, dato l'albero seguente:
La funzione deve restituire il valore -9.
Il programma 9-6-2000-driver.c contiene la funzione di lettura di albero da file, e la chiamata alla funzione DifferenzaAlbero che deve appunto calcolare questa differenza. L'esercizio consiste quindi nella scrittura di questa funzione, più ogni altra funzione ausiliaria necessaria.
Alcuni file con i dati di input (tree3.txt è l'albero vuoto), e le corrispondenti soluzioni, sono riportate qui sotto. La soluzione è composta di due righe: la prima è la stampa dell'albero stesso, la seconda è la stampa del risultato della funzione.
Il testo dice che occorre fare la somma di due sottoalberi, di cui va poi fatta la differenza. Possiamo quindi procedere nel modo seguente: dato che ci serve fare la somma di sottoalberi, scriviamo una funzione che, dato un albero, ne calcola la somma dei nodi. Per trovare la differenza, facciamo poi il calcolo della somma sul sinistro, poi sul destro, e infine la differenza.
Iniziamo scrivendo una funzione che, dato un albero generico, calcola la somma dei suoi nodi. Se l'albero è vuoto, la somma è chiaramente 0. Se l'albero contiene almeno un nodo, usiamo l'ipotesi che le due chiamate ricorsive forniscono il risultato corretto. Quindi, SommaAlbero(a->sinistro) dà la somma dei nodo del sottoalbero sinistro, mentre SommaAlbero(a->destro) è la somma del destro. La somma di tutto l'albero si ottiene sommando questi due valori, più il valore nella radice. La funzione di calcolo della somma dei valori di un albero è quindi la seguente.
int SommaAlbero(TipoAlbero a) {
if(a==NULL)
return 0;
return a->radice+SommaAlbero(a->sinistro)+SommaAlbero(a->destro);
}
La funzione che ci serve deve semplicemente calcolare la somma dei nodi del sottoalbero sinistro e di quello destro. Dato che questi due sottoalberi sono a->sinistro e a->destro, facciamo due chiamate a SommaAlbero passando questi due alberi come parametri. La funzione deve semplicemente restiture la differenza fra i due valori trovati. Il testo non specifica come si deve comportare la funzione nel caso in cui l'albero passato è vuoto. In questo caso, abbiamo assunto che la differenza, in questo caso, sia 0.
int DifferenzaAlbero(TipoAlbero a) {
if(a==NULL)
return 0;
return SommaAlbero(a->sinistro)-SommaAlbero(a->destro);
}
Sia l il puntatore iniziale a una lista di elementi interi, già costruita in memoria con strutture e puntatori. Scrivere una funzione che modifichi la lista nel modo seguente:
La funzione deve rilasciare tutta la memoria dinamica eventualmente non più utilizzata nella lista modificata.
Ad esempio, ricevendo in ingresso la lista seguente (con un numero dispari di elementi)
(4 -4 12 6 -22)
La funzione deve restituire in uscita la seguente lista modificata:
(0 18)
Si noti che l'ultimo elemento è stato correttamente eliminato.
ATTENZIONE: la funzione non deve creare una nuova lista, ma modificare la lista già esistente in memoria.
Il programma driver, in cui va inserita la funzione che risolve il problema, è 26-6-2000-driver.c Il programma legge la lista da file, e il nome di questo file va specificato come argomento del programma.
Risolviamo il problema usando quattro possibili metodi: abbiamo quindi una soluzione ricorsiva e tre soluzioni iterative. In particolare, le soluzioni iterative sono: una soluzione basata sulla progettazione top-down e bottom-up; una soluzione iterativa realizzata con una sola funzione; una soluzione iterativa con uso di un record generatore.
Partiamo dai casi base: se la lista è vuota, non si deve fare niente (non ci sono elementi da eliminare oppure da accorpare). Se la lista ha un solo elemento, allora va eliminato (è un elemento dispari). Se la lista ha due elementi, allora si mette nel primo la somma dei due valori, e si elimina il secondo.
Il terzo caso è quello più interessante. Infatti, dopo aver eliminato il secondo elemento, quello che occorre fare è ripetere la stessa procedura sul resto della lista. Infatti, accorpare il primo e il secondo elemento del resto della lista equivale ad accorpare il terzo e il quarto della lista originale, ecc. Si vede chiaramente che la cosa funziona anche nel caso in cui la lista ha un elemento dispari di elementi: in questo caso, l'ultima chiamata ricorsiva viene fatta su una lista composta da un unico elemento, che viene quindi eliminato (vedi il caso base di sopra).
La funzione complessiva viene riportata qui sotto.
void AccorpaRicorsiva(TipoLista *pl) {
TipoLista s;
/* caso di lista vuota */
if(*pl==NULL)
return;
/* lista di un solo elemento */
if((*pl)->next==NULL) {
free(*pl);
*pl=NULL;
return;
}
/* accorpa primo e secondo */
(*pl)->val=(*pl)->val+(*pl)->next->val;
/* libera il secondo */
s=(*pl)->next->next;
free((*pl)->next);
(*pl)->next=s;
/* chiamata ricorsiva */
AccorpaRicorsiva(&(*pl)->next);
}
Risolviamo il problema in modo iterativo. Da una semplice analisi del problema si intuisce che la eliminazione dell'ultimo elemento (se dispari) e l'accorpamento delle coppie sono due problemi differenti. Infatti, mentre per accorpare una coppia basta l'indirizzo della prima struttura (infatti, qui mettiamo la somma, e poi eliminiamo il successivo elemento), per eliminare l'ultimo elemento serve l'indirizzo della struttura precedente. La soluzione che viene proposta subito dopo questa è basata su una unica funzione iterativa, e si vede che è piuttosto complicata, dato il numero di casi da tenere in considerazione.
Tentiamo invece di risolvere il problema in modo top-down, usando anche il meccanismo bottom-up di usare funzioni che già sappiamo scrivere.
Nel nostro caso, il problema si può scrivere in modo algoritmico, ad alto livello, nel modo seguente:
if( la lista ha un numero dispari di elementi ) elimina ultimo elemento della lista; accorpa gli elementi a coppie
Questo algoritmo contiene tre frasi scritte in italiano, che occorre tradurre in altrettanti frammenti di codice C. In particolare, se un frammento di codice realizza una funzionalità ben definita, è bene realizzarlo usando una funzione separata. Scrivere il codice usando funzioni separate, in modo tale che ogni funzione fa una cosa facilmente definibile è un vantaggio, perchè rende il codice facile da scrivere e da capire, permette il testing modulare del programma, e aumenta la probabilità che il codice sia corretto.
In questo caso, dovremmo scrivere tre funzioni, che fanno queste tre cose:
La seconda cosa da fare corrisponde a una funzione già vista, e quindi non crea nessun problema. Per quello che riguarda il controllo sul numero di elementi, notiamo che in effetti abbiamo già scritto una funzione che conta il numero di elementi di una lista. È quindi conveniente usare questa funzione piuttosto che scriverne una nuova. Per quello che riguarda la funzione di accorpamento, questa va scritta ex-novo. La funzione principale è fatta come segue.
void AccorpaTopDown(TipoLista *pl) {
if(ContaElementi(*pl)%2==1)
EliminaCodaLista(pl);
AccorpaPaia(*pl);
}
Non si riportano qui le funzioni di conteggio elementi e di eliminazione dell'ultimo, perchè già visti in altre pagine, e comunque di facile realizzazione.
Quello che manca è solo la funzione di accorpamento. Notiamo che, per come questa funzione viene chiamata, si ha la garanzia che la lista è composta da un numero pari di elementi: infatti, anche se la lista avesse avuto un numero dispari di elementi, l'ultimo sarebbe stato già eliminato.
Possiamo procedere in questo modo: per ogni elemento della lista, sommiamo ad esso il successivo, e poi eliminiamo il successivo. A questo punto, andiamo avanti con la scansione. L'algoritmo si può quindi scrivere come segue:
while( ci sono ancora elementi ) {
somma il primo elemento con il secondo
elimina il secondo
passa all'elemento successivo
}
Si tratta quindi di una scansione. A ogni passo, si somma l'elemento scandito con il sucessivo. Si elimina poi il successivo. A questo punto, si deve ripetere sul terzo elemento della lista originale, che ora è il secondo (dato che il secondo originale è stato eliminato). Dato che la lista contiene sicuramente un numero pari di elementi, se la lista contiene un elemento allora ne contiene due. Quindi, se la lista contiene ancora un elemento, allora va accorpato con il successivo. Tutto questo ci dice che si può uscire dal ciclo solo quando siamo arrivati alla fine della lista, ossia la lista puntata dal puntatore di scansione è vuota.
Vediamo un esempio di lista, e proviamo a scrivere il codice che corrisponde all'algoritmo di sopra. Per prima cosa, usiamo una variabile s per fare la scansione, per cui la prima istruzione sarà s=l, dove l è l'indirizzo iniziale della lista.
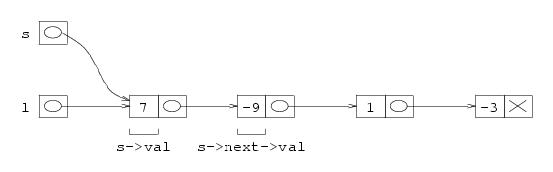
La prima cosa da fare è sommare il secondo elemento al primo. Questo si realizza facendo semplicemente s->val = s->val + s->next->val. Nell'esempio, si sommano 7 e -9, ottenendo -2, che viene messo al posto del 7.

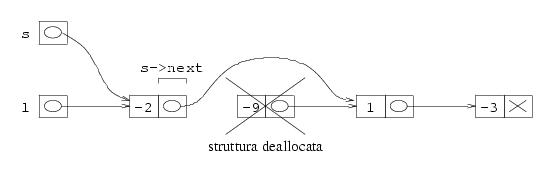
A questo punto, si elimina il secondo elemento della lista. Anche questo è facile: si tratta di modificare s->next, che deve diventare uguale a s->next->next. Dato che la seconda struttura va dellocata, occorre memorizzare il suo indirizzo (che inizialmente si trova in s->next) in una variabile temporanea. Il codice che realizza questa eliminazione è il seguente:
t=s->next; s->next=s->next->next; free(t);
La situazione della memoria dopo l'esecuzione di queste tre istruzioni è la seguente:
A questo punto, occorre ripetere le due fasi di somma ed eliminazione sul terzo e quarto elemento della lista. Si tratta quindi di ripetere le stesse istruzioni, ma prima occorre spostare s sul terzo elemento della lista. Si noti che il terzo elemento della lista originaria è ora il secondo (dato che abbiamo fatto l'eliminazione). Per spostare s in modo che punti al terzo elemento della lista originaria, basta fare s=s->next una sola volta, e si ottiene la situazione seguente:
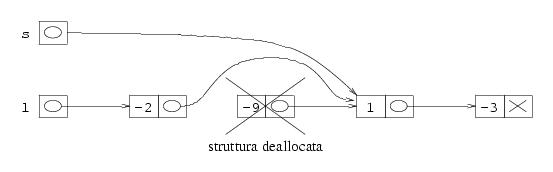
A questo punto, possiamo ripetere le stesse istruzioni. È quindi chiaro che occorre fare un ciclo. Va specificata la condizione di uscita dal ciclo. Si noti che, nella figura di sopra, s->next->next vale NULL, ma il corpo del ciclo va eseguito ancora una volta. Dopo averlo eseguito, abbiamo finito l'accorpamento, e quindi si può uscire dal ciclo. Si vede facilmente che, dopo aver eseguito il corpo del ciclo ancora una volta, la variabile s vale NULL. La condizione di uscita dal ciclo è quindi s!=NULL, che fa uscire dal ciclo quando s vale NULL.
Si noti che il puntatore alla prima struttura della lista non viene mai modificato, per cui la lista si può passare per valore (e si può anche usare l come variabile di scansione). La funzione di accorpamento si può quindi realizzare come segue.
void AccorpaPaia(TipoLista l) {
TipoLista s, t;
s=l;
while(s!=NULL) {
s->val=s->val+s->next->val;
t=s->next;
s->next=s->next->next;
free(t);
s=s->next;
}
}
Rispetto alla soluzione iterativa con una sola funzione riportata qui sotto, questa soluzione presenta almeno due vantaggi:
Rispetto alle soluzioni ricorsive e iterativa con una sola funzione, può sembrare che la soluzione con tre funzioni ausiliarie presenti un problema di efficienza. Infatti, mentre le altre due soluzioni fanno una sola scansione della lista, questa ne fa (nel caso peggiore) tre: una per contare gli elementi, una per eliminare l'ultimo elemento, una per accorpare gli elementi. D'altra parte, il costo di ogni scansione è lineare nella lunghezza della lista, dato che su ogni elemento si fanno un numero costante di operazioni. Questo significa che la soluzione con tre scansioni richiede tempo 3 * c n, dove c è una costante e n il numero di elementi della lista. Quindi, l'intera funzione è lineare esattamente come le altre due: tutte e tre le funzioni sono O(n).
Riassumendo, fare tre volte la scansione di una lista non rappresenta un peggioramento di efficienza, dato che si sta moltiplicando per tre il costo di scansione, e le costanti moltiplicative si ignorano quando si fanno valutazioni di efficienza.
Chi ha deciso di farsi del male può provare a risolvere il problema con una singola funzione che lavora in modo iterativo. La eliminazione degli elementi pari da una lista non presenta grandi difficoltà: si tratta di prendere un elemento, eliminare il successivo, e poi passare al nuovo elemento successivo.
Nel nostro caso, il problema è complicato dal fatto che potremmo arrivare a un elemento della lista che non ha un successore. In questo caso, l'elemento è l'ultimo della lista, e non ha un successore con cui essere accorpato, per cui va cancellato. Serve quindi sapere l'indirizzo della struttura che lo precede.
Abbiamo quindi questa situazione: di solito, ci serve l'indirizzo della struttura di posizione pari, ma alla fine può essere necessario sapere l'indirizzo della struttura precedente. Quindi, dobbiamo sempre sapere l'indirizzo della struttura precedente. Questo fa sí che la funzione debba tenere conto separatamente dei casi in cui la lista ha zero, uno o due elementi. Il ciclo può iniziare solo dopo che il secondo elemento è stato eliminato, per cui ho l'indirizzo della prima struttura, che ora è seguita dalla terza.
void AccorpaIterativa(TipoLista *pl) {
TipoLista s, t;
/* caso di lista vuota */
if(*pl==NULL)
return;
/* lista di un solo elemento */
if((*pl)->next==NULL) {
free(*pl);
*pl=NULL;
return;
}
/* accorpa primo e secondo */
(*pl)->val=(*pl)->val+(*pl)->next->val;
/* libera il secondo */
s=(*pl)->next->next;
free((*pl)->next);
(*pl)->next=s;
/* ciclo sui successivi */
s=*pl;
while(s->next!=NULL) {
/* ho solo un elemento davanti */
if(s->next->next==NULL) {
free(s->next);
s->next=NULL;
return;
}
/* ho due elementi davanti */
s=s->next;
s->val=s->val+s->next->val;
t=s->next->next;
free(s->next);
s->next=t;
}
}
Come si vede, il codice finale è piuttosto complesso. Questo può facilmente portare a degli errori di programmazione. In questo caso, la soluzione ricorsiva è migliore.
Una alternativa a questa soluzione è quella di contare gli elementi della lista con una prima scansione, eliminare l'ultimo se il numero degli elementi è dispari, e poi procedere all'accorpamento degli elementi a coppie. Questo richiede la scansione multipla della lista. Un'altra alternativa possibile è quella di fare prima l'accorpamento, contando nel contempo il numero di elementi della lista: se questo numero è dispari, si fa poi l'eliminazione dell'ultimo elemento (questo richiede comunque la doppia scansione della lista).
La funzione di sopra si può semplificare mediante l'uso dell'elemento generatore. Si parte mettendo un elemento in testa alla lista. Questo ci permette di risparmiare l'accorpamento del primo e secondo elemento, dato che questo viene poi fatto all'interno del ciclo (infatti, il primo e il secondo elemento sono ora diventati il secondo e il terzo, grazie all'elemento generatore).
void AccorpaGeneratore(TipoLista *pl) {
TipoLista s, t;
/* crea il record generatore */
s=*pl;
*pl=malloc(sizeof(struct NodoLista));
(*pl)->next=s;
/* ciclo sui successivi */
s=*pl;
while(s->next!=NULL) {
/* ho solo un elemento davanti */
if(s->next->next==NULL) {
free(s->next);
s->next=NULL;
break; /* attenzione: non return! */
}
/* ho due elementi davanti */
s=s->next;
s->val=s->val+s->next->val;
t=s->next->next;
free(s->next);
s->next=t;
}
/* elimina il record generatore */
s=*pl;
*pl=(*pl)->next;
free(s);
}
In questo caso, occorre prestare attenzione al fatto che ogni punto di uscita della funzione deve contenere l'eliminazione dell'elemento generatore. Non possiamo quindi mettere return in mezzo al ciclo (come veniva fatto nella soluzione precedente) senza aver prima eliminato l'elemento generatore. Il break fa saltare fuori da ciclo, per cui viene eseguita l'eliminazione.
Sia A il puntatore alla radice di un albero i cui nodi contengono valori interi. Si assuma che l'albero sia già presente in memoria. Si scriva una funzione che riceve come parametro questo puntatore, restituisce una lista dei valori interi contenuti nell'albero, nello stesso ordine in cui si trovano visitando l'albero in preordine. In altre parole, stampando la lista si devono ottenere gli stessi elementi, nello stesso ordine, che si ottengono visitando l'albero in preordine.
Ad esempio, dato l'albero seguente:
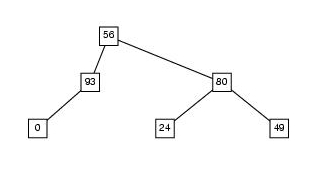
La funzione deve restituire la lista:
(56 93 0 80 24 49)
Il programma 26-9-2000-driver.c contiene le funzioni di lettura di albero da file, di stampa di alberi e liste. Per provare le funzioni, si possono semplicemente scrivere all'interno di questo programma, subito prima di main.
Di serguito vengono dati dei file da usare per il test del programma (tree3.txt è l'albero vuoto). La soluzione è fatta di due righe: la prima è la stampa dell'albero letto, la seconda è la stampa della lista che si ottiene eseguendo la funzione.
La soluzione più semplice è quella di fare la visita dell'albero in preordine, aggiungendo ogni elemento incontrato in coda alla lista. In altre parole, l'algoritmo è il seguente: faccio una visita in preordine dell'albero; la analisi di un nodo non è la stampa del valore, ma la sua aggiunta in coda alla lista.
È chiaro che la aggiunta in coda alla lista si puù realizzare come una funzione. Si tratta in effetti di una funzione che è stata vista a lezione, e che si trova spiegata nel dettaglio in una delle pagine web del corso (inserimento in coda a una lista). Riportiamo una possibile implementazione di questa funzione qui sotto.
void InserisciCodaLista(TipoLista *pl, int e) {
TipoLista s;
/* caso di lista vuota */
if(*pl==NULL) {
*pl=malloc(sizeof(struct NodoLista));
(*pl)->val=e;
(*pl)->next=NULL;
return;
}
/* lista con almeno un elemento: scansione fino alla fine */
s=*pl;
while(s->next!=NULL)
s=s->next;
/* crea un nuovo elemento in coda */
s->next=malloc(sizeof(struct NodoLista));
s=s->next;
s->val=e;
s->next=NULL;
}
La stessa funzione si può anche realizzare in modo ricorsivo, oppure usando il record generatore. Sono tre alternative valide. Si noti che scrivere per esteso il codice della funzione fa parte della soluzione del compito. In altre parole, lo svolgimento dell'esercizio deve contenere la implementazione di tutte le funzioni, anche quelle che sono state viste a lezione.
La lista viene realizzata mediante una funzione di visita, in cui l'operazione di analisi non è la stampa del valore, ma la sua aggiunta in coda alla lista. La funzione ha quindi due parametri: l'albero e la lista in cui l'elemento va aggiunto. La lista va chiaramente passata per indirizzo, dal momento che la aggiunta in coda può modificare il puntatore iniziale.
La funzione si realizza quindi mettendo in coda la radice, e poi visitando i due sottoalberi. Occorre naturalmente tenere conto che l'albero può essere vuoto (caso base della ricorsione): in questo caso, non c'è niente da aggiungere, per cui la funzione termina senza fare modifiche alla lista.
void VisitaInCoda(TipoAlbero a, TipoLista *pl) {
if(a==NULL)
return;
InserisciCodaLista(pl, a->radice);
VisitaInCoda(a->sinistro, pl);
VisitaInCoda(a->destro, pl);
}
La funzione che occorre realizzare deve prendere un albero e restituire una lista, per cui la funzione di sopra non va bene. La funzione che risolve il problema, d'altra parte, deve fare solo due cose: inizializzare la lista a NULL, e lanciare la funzione di visita. Si noti che la inizializzazione è necessaria, dal momento che la funzione di visita non fa mai questa inizializzazione (infatti, si limita solo ad aggiungere in coda alla lista).
TipoLista ListaPreordineCoda(TipoAlbero a) {
TipoLista l;
l=NULL;
VisitaInCoda(a, &l);
return l;
}
Il programma di sopra è quadratico (numero di istruzioni eseguite proporzinale al quadrato del numero di nodi dell'albero). Il problema è che, ogni volta che faccio un inserimento in coda, devo fare la scansione di tutta la lista solo per trovare l'indirizzo dell'ultima struttura. È possibile evitare queste scansioni: nella corso della visita dell'albero mi ricordo l'indirizzo dell'ultima struttura della lista, e aggiungo l'elemento a partire da questo punto. Si noti che la funzione di visita non ha bisogno del puntatore iniziale della lista: infatti, per aggiungere in coda basta l'indirizzo dell'ultima struttura.
La funzione di visita crea quindi un nuovo elemento supponendo di sapere l'indirizzo dell'ultima struttura della lista. Dopo aver fatto la aggiunta in coda, si deve spostare il puntatore (infatti, la aggiunta in coda ha creato un nuovo ultimo elemento della lista). Si continua poi la visita sul sottoalbero sinistro e sul destro.
Si noti che il puntatore all'ultima struttura va passato per indirizzo. Infatti, se il sottoalbero sinistro non è vuoto, allora la prima chiamata ricorsiva aggiunge elementi in coda alla lista, per cui il puntatore all'ultimo elemento deve cambiare (punta al nuovo ultimo elemento della lista). Il programma principale deve vedere questa modifica? Chiaramente sí, dato che deve passare questo valore alla seconda chiamata ricorsiva. Quindi, il puntatore va passato per indirizzo.
void VisitaAggiungi(TipoAlbero a, TipoLista *ps) {
if(a==NULL)
return;
(*ps)->next=malloc(sizeof(struct NodoLista));
(*ps)=(*ps)->next; /* la lista ha un nuovo ultimo elemento */
(*ps)->val=a->radice;
(*ps)->next=NULL;
VisitaAggiungi(a->sinistro, ps);
VisitaAggiungi(a->destro, ps);
}
La funzione di sopra aggiunge la radice in coda alla lista, e poi fa le chiamate ricorsive. Occorre tenere presente che l'aggiunta in coda, cosí come è stata fatta in questa funzione, è corretta solo se la lista contiene già almeno un elemento. La funzione finale deve essere scritta in modo tale che la chiamata alla funzione di visita passi sempre una lista che contiene già almeno un elemento. Abbiamo quindi due soluzioni:
Qui sotto facciamo vedere la funzione che si ottiene implementando la seconda strategia. La funzione principale crea una lista con un elemento, che è quello che si trova nella radice dell'albero. A questo punto, occorre visitare in preordine i due sottoalberi, per cui si fanno due chiamate alla funzione di visita (una sul sottoalbero sinistro e una sul destro).
TipoLista VisitaLista(TipoAlbero a) {
TipoLista l, s;
if(a==NULL)
return NULL;
l=malloc(sizeof(struct NodoLista));
l->val=a->radice;
l->next=NULL;
s=l;
VisitaAggiungi(a->sinistro, &s);
VisitaAggiungi(a->destro, &s);
return l;
}
Esistono ovviamente della soluzioni alternative: una è quella di creare un elemento fittizio nella lista (elemento generatore), fare la visita a partire dalla radice, e poi eliminare il primo elemento dalla lista. Un'altra possibile soluzione è quella di modificare la funzione di visita in modo da renderla corretta anche quando la lista non è vuota (questo chiaramente è possibile solo se la funzione riceve anche il puntatore iniziale della lista).
Scrivere una funzione che prende come parametro un grafo e restituisce una lista che contiene i nodi del grafo che hanno almeno due successori. Dare la dichiarazione di tipo della lista, e scrivere tutte le funzioni su liste necessarie alla soluzione del problema. Si assuma che le dichiarazioni di tipo del grafo, e le operazioni fondamentali, siano già state scritte. La funzione deve andare bene, senza modifiche, con entrambe le rappresentazioni dei grafi.
Esempio: se la funzione riceve come parametro il grafo qui sotto a sinistra, deve restituire la lista (1 2 4), dal momento che questi sono i nodi che hanno due (o più) successori.
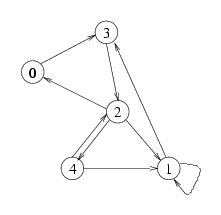
Il programma driver, che contiene la definizione di grafo, con le operazioni di lettura da file, è 4-6-2001-driver.c Questo programma contiene già la funzione di stampa di una lista, ma il tipo lista deve essere definito: la soluzione, che comprende anche la definizione del tipo lista, va messa nel punto del programma in cui appare il commento /* inserire qui la soluzione */
Alcuni file con possibili dati di input, e le corrispondenti soluzioni, sono riportate qui sotto. La soluzione è composta di due parti: la prima è la stampa del grafo stesso (un utile controllo per verificare se il grafo è stato scritto su file correttamente), la seconda è la stampa del risultato della funzione (la lista dei nodi con almeno due successori).
[an error occurred while processing this directive]
Ad alto livello si può descrivere la soluzione del problema come segue: per ogni nodo del grafo, se ha almeno due successori, lo si mette nella lista. Il primo livello di raffinamento dell'algoritmo è quindi quello che segue:
per ogni nodo del grafo
se il nodo ha almeno due successori
metti il nodo in lista
Per prima cosa, la lista deve essere inizialmente vuota. La scansione dei nodi del grafo corrisponde a un ciclo for, mentre per l'inserimento in lista possiamo usare la funzione di inserimento in testa a una lista. Per quello che riguarda il controllo del numero dei successori, possiamo usare una funzione che calcola il numero dei successori di un nodo. La funzione che si ottiene è quindi la seguente:
TipoLista ListaDueSuccessori(TipoGrafo g) {
TipoLista l;
int i;
l=NULL;
for(i=0; i<=NUMNODI-1; i++)
if( NumeroSuccessori(g, i) >= 2 )
InserisciTestaLista(&l, i);
return l;
}
Sviuppiamo ora le funzioni usate da questa. Per l'inserimento in lista non abbiamo problemi (è una delle funzioni sulle liste vista a lezione). Il conteggio del numero dei successori si può fare usando un contatore che parte da 0. Per ogni nodo, se c'è un arco dal nodo passato a questo, si incrementa il contatore.
Conteggio successori di i:
contatore=0;
per ogni nodo j
se c'è un arco da i a j
incrementa contatore
Alla fine, il contatore contiene il numero dei successori del nodo. L'implementazione è a questo punto immediata:
int NumeroSuccessori(TipoGrafo g, int i) {
int j, nsucc;
nsucc=0;
for(j=0; j<=NUMNODI-1; j++)
if(TestEsisteArco(g, i, j))
nsucc++;
return nsucc;
}
Si noti che questa funzione usa TestEsisteArco. È importante notare che il testo dell'esercizio richiede che la funzione da implementare sia fatta in modo tale da funzionare, senza modifiche, con entrambe le rappresentazioni dei grafi. Questo significa che l'unico modo possibile per verificare l'esistenza di archi è quello di usare TestEsisteArco (assumere che si stia usando la matrice di adiacenza o la lista dei successori è un errore).
Si può risolvere il problema anche usando una singola funzione. Quando possibile, è bene invece cercare di ridurre il problema da risolvere in sottoproblemi, dato che questo facilita l'operazione di soluzione, e permette di evitare maggiormente la generazione di errori nel codice.
compito luglio 2001 (non ancora disponibile)Scrivere una funzione che riceve come parametri un albero (i cui nodi sono etichettati con interi) e una lista di interi; la funzione ritorna un valore booleano, che è TRUE se tutti i valori della lista si trovano nell'albero. In altre parole, la funzione dice se ogni intero della lista si trova come etichetta in qualche nodo dell'albero.
Per esempio, dato l'albero a riportato qui sotto, e la lista l=(-42 6 18), la chiamata listainalbero(a, l) deve ritornare TRUE. Se invece si passa la lista s=(6 18 12 -43) allora la chiamata deve restituire FALSE, perchè il numero 12, che si trova nella lista, non sta nell'albero.
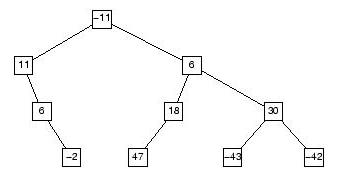
Il programma driver, in cui va inserita la funzione che risolve il problema, è listainalbero-driver.c Il programma prende come parametri i nomi di due file, il primo contentente l'albero e il secondo contente la lista.
Il testo del problema può venire riformulato come segue: per ogni elemento della lista, verifica se si trova nell'albero. È quindi chiaro che occorre prima fare una scansione della lista, dal momento che questo è l'unico modo per poter effettuare una stessa operazione (la verifica di presenza nell'albero, in questo caso) su tutti gli elementi della lista.
per ogni elemento della lista verifica se si trova nell'albero
Assumiamo quindi che esista una funzione presente() che prende come parametri un intero e un albero, e restituisce un booleano che indica se l'intero si trova o meno nell'albero (questa funzione verraà poi sviluppata).
Avendo lasciato a un successivo sviluppo la funzione che verifica la presenza di un intero in albero, quello che resta da fare è una scansione della lista, verificando la presenza dell'elemento nell'albero ad ogni passo. La funzione segue lo schema classico della scansione della lista (ma in più la funzione prende come parametro un albero):
bool listainalbero(TipoAlbero a, TipoLista l) {
TipoLista s;
s=l;
while(s!=NULL) {
/* operazione da fare su ogni elemento della lista */
s=s->next;
}
}
L'unica cosa che va ancora specificata è l'operazione da fare su ogni elemento della lista. In questo caso, occorre verificare se l'elemento di trova nell'albero, per cui sicuramente va fatta una chiamata alla funzione presente passando come parametri l'elemento, ossia s->val, e l'albero, che in questo caso si trova nella variabile a. Quindi, al posto del commento, va messa la chiamata di funzione presente(a, s->val).
La funzione presente non modifica i suoi argomenti, ma si limita a ritornare un valore booleano che indica se l'elemento di trova o meno nell'albero. Cosa ci facciamo con questo valore? Se è FALSE, allora l'elemento non si trova nell'albero. Dal momento che abbiamo trovato un elemento della lista che non sta nell'albero, possiamo sicuramente concludere che non è vero che tutti gli elementi della lista sono nell'albero. Quindi, se la funzione presente ritorna FALSE, la funzione di verifica su tutti gli elementi della lista può semplicemente ritornare FALSE, senza proseguire la scansione.
Nel caso in cui la funzione ritorna TRUE, sappiamo che l'elemento corrente si trova nell'albero. Non possiamo però concludere che la verifica è riuscita, dal momento che occorre ancora controllare se la stessa cosa vale anche per gli elementi successivi. Quindi, se la chiamata presente(a, s->val) ritorna TRUE, occorre proseguire la scansione come al solito. Al posto del commento dobbiamo quindi mettere la chiamata alla funzione presente con una verifica del suo valore di ritorno, a seconda del quale la funzione listainalbero può ritornare a sua volta FALSE.
bool listainalbero(TipoAlbero a, TipoLista l) {
TipoLista s;
s=l;
while(s!=NULL) {
if( !presente(a, s->val) )
return FALSE;
s=s->next;
}
}
Manca ora solo un ultimo dettaglio: la funzione deve ritornare un valore booleano, e questo accade in effetti se la chiamata presente(a, s->val) ritorna FALSE su un qualsiasi elemento (e si ritorna il valore FALSE). D'altra parte, se questo non avviene per nessun elemento della lista, il ciclo termina senza aver mai eseguito il return, e dopo il ciclo non ci sono altre istruzioni. Ci troviamo quindi in una situazione in cui una funzione che dovrebbe ritornare un valore booleano non esegue una istruzione di return, che è necessaria appunto per ritornare questo valore.
La soluzione è semplice: aggiungiamo una istruzione di return alla fine della funzione. Quale è il valore da ritornare? È possibile capirlo a partire dalla situazione che ci ha portati alla fine della funzione senza effettuare il ritorno: questo infatti può avvenire soltanto se non abbiamo mai trovato un valore nella lista che non stesse anche nell'albero. Questo frase si può anche scrivere come: ``ogni elemento visitato sta nell'albero''; sono due frasi con lo stesso significato. Quindi, se ci troviamo alla fine della funzione, vuol dire che:
Il secondo punto è una conseguenza del fatto che abbiamo fatto una scansione classical della lista, e che non siamo ritornati prima. Possiamo quindi concludere che, secondo il testo del problema, la funzione deve ritornare TRUE, dato che tutti gli elementi della lista stanno nell'albero.
Veniamo ora alla funzione di verifica di presenza di un intero in un albero, ossia presente, che avevamo prima lasciato in sospeso. Questa funzione deve verificare se l'intero è uguale a un qualche nodo dell'albero. È quindi necessario visitare tutti i nodi dell'albero per verificare se si trova un nodo con quel valore.
Questa funzione si può realizzare seguendo due svolgimenti differenti: il primo è basato sulla definizione ricorsiva, il secondo è una modifica della visita di un albero.
Iniziamo quindi con la versione ricorsiva. I punti di partenza sono, come al solito:
Secondo la definizione, un albero è vuoto oppure contiene un nodo e due sottoalberi. La funzione deve ritornare il risultato corretto in entrambi i casi. Nel primo caso la soluzione è facile: se un albero è vuoto non può contenere un nodo con un valore dato, quindi si ritorna FALSE senza neanche andare a vedere il valore dell'intero da cercare:
bool presente(TipoAlbero a, int x) {
if(a==NULL)
return FALSE;
/* finire */
}
Nel caso in cui l'albero non è vuoto, allora abbiamo un nodo e due sottoalberi. La funzione deve risultare corretta anche in questo caso. Se il nodo (radice) coincide con il valore da cercare, possiamo direttamente restituire TRUE, dato che sappiamo che il valore cercato si trova nell'albero.
bool presente(TipoAlbero a, int x) {
if(a==NULL)
return FALSE;
if(a->info==x)
return TRUE;
/* finire */
}
Se il nodo radice non contiene il valore cercato, non possiamo ancora sapere se restituire TRUE oppure FALSE, dato che il valore potrebbe o no trovarsi nei sottoalberi. Occorre quindi cercare il valore nei sottoalberi. Qui entra in gioco l'ipotesi di correttezza della chiamate ricorsive: possiamo infatti assumere che le due chiamate presente(a->sinistro, x) e presente(a->destro, x) ritornano entrambe il valore corretto. Dovendo verificare se il valore si trova nel sottoalbero sinistro possiamo quindi effettuare la chiamata presente(a->sinistro, x) con la certezza che il valore ritornato è corretto. La stessa cosa per la ricerca nel sottoalbero destro.
Quello che ci manca è ancora il valore di ritorno della funzione che stiamo scrivendo. Abbiamo detto che l'albero non è vuoto, e che il valore da cercare non è nella radice. Facciamo quindi le due chiamate ricorsive per cercare il valore nei due sottoalberi. A questo punto, il valore sta nell'albero se e solo se sta in almeno uno dei due sottoalberi, e questo avviene se almeno una delle due chiamate ricorsive ritorna TRUE. Possiamo quindi dire che la verifica riesce se e solo se una delle due funzioni ritorna TRUE. Dato che in questo caso la funzione deve a sua volta restituire TRUE, possiamo mettere una istruzione di ritorno che restituisce al chiamate l'or dei risultati delle due chiamate ricorsive. La funzione complessiva è quindi la seguente:
bool presente(TipoAlbero a, int x) {
if(a==NULL)
return FALSE;
if(a->info==x)
return TRUE;
return presente(a->sinistro, x) || presente(a->destro, x);
}
Passiamo ora allo sviluppo della stessa funzione usando la modifica della visita. Come si vedrà, la funzione risultante è assolutamente identica, anche se la realizziamo ora seguendo un procedimento diverso.
La visita in preordine di un albero si effettua in questo modo: se l'albero è vuoto, non si fa nulla; se contiene almeno un nodo, lo si visita e si passa poi alla visita dei due sottoalberi, in ordine. Lo schema è quindi il seguente:
void visita(TipoAlbero a) {
if(a==NULL)
return;
operazione_sul_nodo(a->info);
visita(a->sinistro);
visita(a->destro);
}
Questo schema di visita va modificato tenendo presente che l'operazione di verifica sul nodo è quella di confronto con il valore intero passato come parametro. Abbiamo quindi una prima versione:
void presente(TipoAlbero a, int x) {
if(a==NULL)
return;
verifica a->into == x
presente(a->sinistro);
presente(a->destro);
}
A parte il nome della funzione, si tratta solo di un caso particolare di visita. Quello che ci manca, in effetti, sono i valori di ritorno. Infatti, la funzione ritorna un booleano, cosí come le due chiamate ricorsive. E anche la verifica se a->info==x ritorna in effetti un valore booleano. Mettendo insieme tutti questi valori dobbiamo arrivare al valore di ritorno della funzione, ossia dobbiamo riuscire a scrivere le istruzioni return corrette.
In questo caso, la cosa è facile: se a un certo punto della visita troviamo il valore, dobbiamo semplicemente ritornare TRUE. Quindi, se ci troviamo a visitare un nodo che contiene il valore, ritorniamo TRUE. Questo valore positivo si deve poi propagare ``in su'', ossia deve raggiungere la radice dell'albero. Quando un chiamata termina, ci ritroviamo nel punto in cui la funzione è stata chiamata. Se quindi abbiamo fatto la chiamata sul sottoalbero sinistro, ci ritroviamo subito dopo l'istruzione presente(a->sinistro), altrimenti siamo dopo l'istruzione presente(a->destro). In tutti e due i casi, se abbiamo trovato TRUE, dobbiamo chiudere la chiamata ricorsiva comunicando questo valore in modo che arrivi alla radice.
void presente(TipoAlbero a, int x) {
if(a==NULL)
return;
if(a->into == x)
return TRUE;
if(presente(a->sinistro))
return TRUE;
if(presente(a->destro))
return TRUE;
}
Mancano ora gli ultimi due casi: cosa succede se nessuna della due chiamata ha ritornato TRUE? Questo indica che nel corso della visita il valore non è stato trovato, per cui possiamo mettere return FALSE per indicare che la ricerca nel nodo e nei sottoalberi è fallita.
L'ultimo caso è quello del puntatore nullo. Questo si può verificare o perchè l'albero di partenza è vuoto, oppure perchè siamo arrivati a un nodo che non ha uno dei figli. Nel primo caso, ritorniamo FALSE, per i motivi detti prima (un albero vuoto non contiene nessun valore, e in particolare non contiene quello cercato). Nel secondo caso, si vede chiaramente che tornare TRUE farebbe risalire questo valore fino alla radice anche se il nodo non è in effetti stato trovato. Ritornare invece FALSE ha l'effetto di far continuare la ricerca dell'elemento sull'altro sottoalbero. È quindi questo il valore da ritornare. Possiamo quindi concludere che a==NULL deve produrre return FALSE in entrambi i casi in cui questo si verifica.
void presente(TipoAlbero a, int x) {
if(a==NULL)
return FALSE;
if(a->into == x)
return TRUE;
if(presente(a->sinistro))
return TRUE;
if(presente(a->destro))
return TRUE;
return FALSE;
}
Le ultime cinque righe della funzione si possono ora condensare, dal momento che si esegue return TRUE se e solo se una delle due chiamate ritorna TRUE, e si esegue invece return FALSE altrimenti. Quindi, il valore che viene ritornato è TRUE se e solo se uno dei due valori è TRUE, e questo corrisponde a un or.
bool presente(TipoAlbero a, int x) {
if(a==NULL)
return FALSE;
if(a->info==x)
return TRUE;
return presente(a->sinistro, x) || presente(a->destro, x);
}
La soluzione dell'esercizio consiste nelle due funzioni presente e alberoinlista. Si veda anche il programma completo listainalbero.c
Scrivere una funzione che prende come parametro una lista di caratteri che formano una sequenza di parole, separate da spazi (la lista contiene solo lettere e spazi), e restituisce la lista formata dalle lettere iniziali di ogni parola, nell'ordine in cui le parole appaiono nella lista.
Se per esempio la lista di partenza contiene la sequenza di caratteri frase che non vuole dire niente allora la lista che deve venire restituita è fcnvdn. Il programma driver, che legge una lista da file e chiama la funzione CreaListaAcronimo da realizzare è gen02-driver.c. La seguente lista dà alcuni file che si possono usare per testare il programma: lischar1.txt, lischar2.txt (lista vuota), lischar3.txt, lischar4.txt, lischar5.txt, lischar6.txt, lischar7.txt, lischar8.txt,
Il testo dell'esercizio si può rifrasare come segue: data una lista, costruire una seconda lista che contiene solo alcune lettere della prima. In particolare, la seconda lista contiene una lettera della prima solo se questa è la lettera iniziale di una parola.
Possiamo quindi dire che si tratta di selezionare le lettere della prima lista che sono lettere iniziali di una parola; queste lettere vanno messe nella seconda lista. Per fare questo è ovviamente necessario verificare, per ogni elemento della prima lista, se soddisfa la condizione di essere inizio di una parola, nel qual caso la lettera va messa nella seconda lista.
per ogni elemento della prima lista
se e' l'inizio di una parola
allora mettilo nella seconda lista
La prima linea, ossia la frase per ogni elemento della prima lista si traduce in C in una scansione della lista, e non presenta nessuna difficoltà.
Veniamo ora invece alla traduzione della frase se e' l'inizio di una parola. Occorre rendere questa frase meno ambigua, ossia va prima trasformata in modo che specifichi in modo esatto come si fa a capire se una lettera è l'inizio di una parola.
Possiamo però sfruttare l'assunzione che la lista contiene solo lettere e spazi. Questo significa che la lista contiene delle sequenza di lettere intervallate da uno o più spazi, e le sequenze di lettere sono appunto le parole. Questo significa che una parola inizia quando:
Il secondo punto si può ulteriormente semplificare notando che la parola in effetti inizia quando uno spazio è seguito da una lettera. Quindi, un elemento della prima lista è l'inizio di una parola se è il primo carattere della lista ed è una lettera, oppure se è preceduto da un carattere.
Il primo punto è facile da verificare: basta controllare se il primo elemento della lista è una lettera, e quindi si può anche fare fuori dal ciclo di scansione della prima lista.
if(l==NULL)
return NULL;
if(l->val!=' ') {
s=malloc(sizeof(struct NodoLista));
s->val=l->val;
s->next=NULL;
}
/* scansione della lista */
Verificare se un elemento è preceduto da uno spazio è invece più difficile. Infatti, una volta che ci troviamo a scandire un carattere, non abbiamo un modo facile di vedere qual'è l'elemento che lo precede (la cosa è invece banale nel caso dei vettori, in cui basta diminuire di uno l'indice).
Sono però possibili due soluzioni. La prima è quella di memorizzare l'elemento corrente prima di avanzare il puntatore: questo elemento risulta quindi il precedente nel successivo corpo del ciclo di scansione. Il secondo modo consiste nel modificare ulteriormente la definizione di inizio di parola; infatti, possiamo dire che una parola inizia quando uno spazio è seguito da una lettera, e che la lettera (quindi, l'elemento successivo) è l'iniziale della parola.
Iniziamo quindi ad analizzare la prima soluzione. L'idea è la seguente: se ho finito di analizzare un elemento della lista l->val e sto per passare al successivo facendo l=l->val, allora l'elemento che ora è quello corrente dopo questa istruzione diventa l'elemento precedente. D'altra parte, non posso più accedere ad esso, dal momento che il puntatore l è stato portato avanti. Occorre quindi memorizzare l'elemento prima che il puntatore vada avanti. Per fare questo, posso utilizzare una variabile di tipo carattere. In breve, se abbiamo la sequenza di istruzioni:
c=l->val; l=l->next;
Allora c è un elemento della lista, mentre alla fine l punta all'elemento successivo. In altre parole, c è l'elemento precedente a quello puntato da l.
La soluzione, a questo punto, &ovvia: si fa una scansione della lista, memorizzando nella variabile c il valore dell'elemento precedente. Ad ogni elemeno della lista, si vede se l'elemento è una lettera, e se il precedente è uno spazio. In questo caso, si aggiunge il carattere corrente alla lista.
c=l->val;
l=l->next;
while(l!=NULL) {
if(l->val!=' ' && c==' ')
/* inserisci l->val nella lista s */
c=l->val;
l=l->next;
}
Si faccia attenzione alle prime due istruzioni: dal momento la scelta se inserire o meno un elemento dipende dall'elemento e dall'elemento precedente, è necessario che la scansione venga fatta solo su elementi per i quali esiste un elemento precedente. Infatti, inseriamo un elemento in lista solo se è una lettera e il precedente è uno spazio, e questo confrono ha senso solo se l'elemento corrente ha un precedente da confrontare con lo spazio.
A prima vista la cosa non crea problemi: tutti gli elementi della lista hanno un precedente? Questo è vero per quasi tutti gli elementi della lista, o meglio, tutti tranne il primo, che non ha un elemento precedente. Quindi, dato che la scansione va fatta solo su elementi che hanno un elemento precedente, occorre iniziare la scansione a partire dal secondo elemento della lista. Questo spiega l'istruzione l=l->next; che precede l'intero ciclo. Prima ancora viene effettuato l'assegnamento c=l->val che memorizza il primo elemento in c, in modo tale che, alla prima esecuzione del ciclo contenga correttamente il valore dell'elemento precedente.
Quello che manca, a questo punto, è l'inserimento del carattere nella lista risultato. In questo caso, vogliamo che le lettere iniziali delle parole vangano inserite nello stesso ordine in cui le lettere stesse sono state incontrate durante la scansione della lista.
Supponiamo quindi che la lista che è stata passata come parametro sia appunto frase che non vuole dire niente, e vediamo in che modo le lettere vanno inserite. Il primo carattere della lista è l, per cui viene messo nella lista risultato prima ancora di iniziare il ciclo di scansione. A questo punto la lista r contiene un solo elemento, la lettera f.
Quando la scansione arriva alla lettera c, da cui inizia la seconda parole, abbiamo quindi il carattere c da inserire, e la lista è composta dalla sola lettera f. Dova va messa la c? In questo caso f è l'iniziale della prima parola, mentre c è l'iniziale della seconda. Quindi la c va messa dopo la lettera f.
La lista che risulta è quindi fc. Continuiamo quindi la scansione, e arriviamo alla n da cui inizia la parola non. Ora, questa è la terza parola, per cui la lettera va messa dopo le altre due. Quando si arriva alla quarta parola vuol, la v iniziale va messa in quarta posizione, ossia dopo le altre. Lo stesso vale per la quinta lettera ecc.
In generale, possiamo dire semplicemente che, quando si arriva a una nuova lettera da inserire, questa va messa dopo quelle che sono state trovate fino a quel momento. Quindi, l'inserimento da fare è quello in coda alla lista.
TipoLista CreaListaAcronimo(TipoLista l) {
TipoLista a;
char c;
if(l==NULL)
return NULL;
a=NULL;
if(l->val!=' ')
InserisciCodaLista(&a, l->val);
c=l->val;
l=l->next;
while(l!=NULL) {
if(c==' ' && l->val!=' ')
InserisciCodaLista(&a, l->val);
c=l->val;
l=l->next;
}
return a;
}
La funzione di inserimento in coda si può sia in modo iterativo che in modo ricorsivo. Entrambi i metodi sono stati visti a lezione, e si trovano anche sul libro. Di seguito, ecco il link all'inserimento in coda iterativo. La versione ricorsiva è simile alla cancellazione dell'ultimo elemento ricorsiva.
Consideriamo ora il secondo metodo di soluzione a cui si è accennato, ossia quello di fare la scansione controllando se il carattere corrente sia uno spazio mentre il successivo è una lettera.
In questo caso, la scansione va iniziata dal primo elemento della lista. Può anche darsi il caso che il primo carattere della lista sia uno spazio, seguito da una lettera; in questo caso, occorre fare il controllo anche sul primo elemento della lista, dato che il controllo infatti dice che il successivo elemento è l'inizio di una parola.
Il ciclo consiste quindi in una scansione della lista, in cui ad ogni passo si controlla se l->val è uno spazio mentre l->next->val è una lettera. Se entrambe le condizioni sono vere, il carattere da inserire in lista è il successivo, ossia l->next->val.
Si noti che, ad ogni passo, si fa un accesso all'elemento puntato da l->next. È quindi necessario fare in modo che questo puntatore non sia mai NULL. In altre parole, l'ultimo confronto significativo è quello che viene fatto con il penultimo e l'ultimo elemento. Infatti, se si trova che il penultimo è uno spazio e l'ultimo è una lettera, mettiamo l'ultimo in lista. Altrimenti, abbiamo esaurito la lista, e non ci sono altre possibilità di passare da uno spazio a una lettera.
Tutto questo ci dice che il ciclo di scansione, in questo caso, inizia dal primo elemento della lista (e non dal secondo come nel caso precedente), e termina con il penultimo elemento (e non con l'ultimo).
Anche in questo caso occorre fare prima il controllo sul primo elemento della lista (se è una lettera va messo in lista), e anche in questo caso l'inserimento in lista va fatto in coda. La funzione risultante è quindi la seguente.
TipoLista CreaListaAcronimo(TipoLista l) {
TipoLista a;
if(l==NULL)
return NULL;
a=NULL;
if(l->val!=' ')
InserisciCodaLista(&a, l->val);
while(l->next!=NULL) {
if(l->val==' ' && l->next->val!=' ')
InserisciCodaLista(&a, l->next->val);
l=l->next;
}
return a;
}
Esistono delle varianti di queste due soluzioni. Per esempio, la prima soluzione funziona ugualmente se non si effettua il controllo sul primo elemento, ma si pone inizialmente c=' ' e poi si fa la scansione a partire dal primo elemento della lista, invece che dal secondo. In questo modo, se il primo elemento è una lettera, alla prima esecuzione del ciclo risulta vero sia che c è uno spazio, sia che l'elemento corrente è una lettera, e quindi il primo elemento viene correttamente inserito in lista.
È poi possibile sostutire l'inserimento in coda con l'inserimento in testa. Questo però genera una lista in cui l'ordine delle lettere è invertito. Per ottenere l'ordine giusto, occorre quindi invertire la lista prima di ritornarla. La funzione di inversione di una lista si trova sul libro.
Una ultima soluzione comporta l'inserimento in coda alla lista, ma senza usare una funzione separata, ma mantenendo un puntatore all'ultimo elemento della lista che si sta costruendo. Questa soluzione è quella più complessa, ed è quindi quella che più facilmente può portare a errori.
Testo
Scrivere una funzione che ha come parametro una lista e restituisce un intero che indica la posizione della lista in cui appare per la prima volta un elemento uguale all'ultimo.
Per esempio, se la lista è 3 9 2 4 2 3 5 2 2 allora la funzione deve restituire 3, dal momento che l'ultimo elemento della lista è 2, e la prima posizione in cui appare il 2 è la terza.
Valutazione per questo esercizio:
Driver e file di prova
Programma driver: 9lug02-driver.c La soluzione va inserita dove appare il commento /* inserire qui la soluzione */, e deve avere il prototipo:
int PrimaPosizioneUltimo(TipoLista);
Il nome del file che contiene la lista che viene passata alla funzione va dato da linea di comando (da prompt dei comandi, si fa 9lug02-driver nomefile, mentre dal TurboC si può impostare il nome del file nel menu Run->Arguments). Alcuni possibili file di prova, con i valori che devono risultare, sono i seguenti:
| File lista | Risultato funzione |
|---|---|
| lista0.txt (lista vuota) | 0 |
| lista1.txt | 1 |
| lista2.txt | 1 |
| lista3.txt | 6 |
| lista4.txt | 1 |
| lista5.txt | 2 |
| lista6.txt | 4 |
Soluzione
La soluzione di questo esercizio richiede esplicitamente di costruire l'algoritmo in raffinamenti successivi. In ogni caso, questa operazione è suggerita, perchè in genere consente di ottenere l'algoritmo più semplice, e al tempo stesso costituisce una documentazione della soluzione. La parte due (spiegazione a parole) è una spiegazione degli algoritmi e del codice. Quanto scritto qui sotto è un possibile esempio di spiegazione a parole della soluzione.
L'esercizio richiede di trovare la posizione del primo elemento che coincide con l'ultimo. Possiamo quindi pensare di scomporre l'algoritmo in due parti.
trova il valore dell'ultimo elemento trova la posizione in cui questo elemento appare
Quello riportato qui sopra è il primo livello di raffinamento dell'algoritmo. A questo manca ancora la considerazione del caso particolare di lista vuota (in questo caso, va restituito il valore 0). Va quindi aggiunto un if iniziale.
Per quello che riguarda lo sviluppo dei due punti (trovare l'ultimo elemento e trovare la posizione di un elemento in una lista), possiamo pensare di sviluppare entrambe la parti all'interno di una sola funzione, oppure di realizzare una funzione per ognuna di esse. In questo caso, entrambi i passi consistono nella realizzazione di una funzionalità ben precisa, per cui è opportuno realizzare una funzione separata per ognuna delle due fasi. Si ricordi che una regola empirica per capire quando è bene fare una funzione è:
se si riesce a descrivere ciò che una parte di codice fa in poche parole, allora è opportuno realizzare una funzione
Nel nostro caso, la prima parte dell'algoritmo consiste nel ``trovare l'ultimo elemento di una lista''. A parte il fatto che questa funzione è già nota, la sua semplice descrizione ci fa capire che è opportuno realizzare una funzione. La seconda parte si descrive come ``trovare la prima posizione in cui appare un elemento''. La semplicità della descrizione fa capire che è bene realizzare una funzione.
Iniziamo quindi a sviluppare la prima funzione. In questo caso, il successivo livello di raffinamento dell'algoritmo coincide quasi con il codice finale: per trovare l'ultimo elemento di una lista, si fa una scansione fino alla fine.
scansione della lista fino all'ultimo elemento restituzione ultimo elemento
La scansione della lista fino all'ultimo elemento è stata già vista, e consiste nel portare avanti un puntatore finchè il campo next della struttura puntata non vale NULL (si vedano le pagine sulle liste). Abbiamo quindi il seguente codice finale:
int UltimoLista(TipoLista l) {
while(l->next != NULL)
l=l->next;
return l->val;
}
Si tenga presente che la funzione va in errore se la lista è vuota. Prima di chiamare questa funzione, quindi, è necessario controllare che la lista passata non sia vuota.
Passiamo ora alla seconda funzione ausiliaria, ossia quella in cui si trova la prima posizione in cui un elemento appare. È opportuno relizzare la funzione in base alla sua specifica, e non in base all'uso che ne facciamo. In questo caso, la funzione deve trovare la prima occorrenza di un elemento, quindi possiamo anche pensare che l'elemento non sia presente, anche se nel caso specifico in cui usiamo questa funzione questo caso non si può presentare. L'algoritmo risolutivo è il seguente: inizializziamo un contatore; per ogni elemento della lista, se è quello da trovare ritorniamo il contatore, altrimenti lo aumentiamo di uno. Se alla fine non si è trovato l'elemento, possiamo ritornare 0 oppure -1 per indicare che l'elemento non è stato trovato.
contatore=1;
per ogni elemento della lista {
se è quello da cercare
return contatore
contatore++
}
return -1
Il codice finale si ottiene semplicemente convertendo la frase ``per ogni elemento della lista'' in una scansione lineare della lista.
int PrimaPosizioneElemento(TipoLista l, int e) {
int cont=1;
while(l!=NULL) {
if(l->val==e)
return cont;
cont++;
l=l->next;
}
return -1;
}
La funzione complessiva consiste nella chiamata di queste due funzioni, preceduta dal controllo di lista vuota.
int PrimaPosizioneUltimo(TipoLista l) {
int ultimo;
if(l==NULL)
return 0;
ultimo=UltimoLista(l);
return PrimaPosizioneElemento(l, ultimo);
}
Si può facilmente verificare che la funzione è corretta anche nei casi limite (lista di un solo elemento, lista in cui l'ultimo elemento appare per la prima volta in prima posizione, lista in cui l'ultimo elemento appare solo in ultima posizione).
Testo
Un albero di interi viene memorizzato in un file binario, usando lo stesso metodo che si usa per rappresentare gli alberi con vettori.
Soluzione
Le prime due parti consistono nella descrizione di argomenti svolti a lezione (i file binari sono anche descritti nelle pagine web sui file binari).
La terza parte richede di capire in che modo gli interi e i booleani sono rappresentati su file binario. L'idea è che, sul file, abbiamo gli stessi dati che andrebbero messi nel vettore. Possiamo quindi mettere nel file, sequenzialmente, le strutture che starebbero nel vettore. In alternativa, possiamo memorizzare nel file prima l'intero e poi il booelano, poi il secondo intero e il secondo booleano, ecc.
Consideriamo quindi questa seconda soluzione: il file contiene gli stessi elementi del vettore, nello stesso ordine; l'unica differenza è che il file binario è un file ``piatto'', con la sequenza intero-booleano-intero-booleano- invece delle strutture. A parte questo, l'ordine è lo stesso.
Per quello che riguarda la visita: l'algoritmo di visita, quello indipendente dalla rappresentazione, è il seguente:
visita(albero) {
se l'albero è vuoto
termina la visita
analizza radice
visita(sottoalbero sinistro)
visita(sottoalbero destro)
}
Si noti che l'uso di espressioni come a->sinistro e a->destro è errato per due motivi: primo, siamo a un livello di raffinamento dell'algoritmo in cui non abbiamo ancora specificato la rappresentazione dei dati; secondo, stiamo usando una rappresentazione degli alberi in cui non usiamo le strutture (quindi i campi sinistro e destro non esistono.
La visita di un albero rappresentato come vettore si fa passando la posizione dell'elemento da visitare (radice del sottoalbero da visitare). Nel nostro caso facciamo lo stesso, ossia aggiungiamo un argomento che indica il numero d'ordine dell'elemento da visitare.
visita(albero, pos) {
se l'albero è vuoto
termina la visita
analizza elemento pos
visita(albero, 2*pos+1)
visita(albero, 2*pos+2)
}
L'unico problema che rimane, a questo punto, è come trovare l'elemento di indice pos. Questo si ottiene facilmente dalla considerazione che ogni nodo, che nel vettore occupa una posizione, sul file binario occupa 2*sizeof(int) byte, dato che abbiamo un intero più un booleano (che viene sempre rappresentato come intero). Per questa ragione, l'elemento in posizione pos, che nel vettore era semplicemente a[pos], si ottiene ora facendo una fseek in posizione pos*2*sizeof(int) seguita da una fread di un intero. Una successiva fread legge il campo booleano.
La minima risposta che era necessario dare per questo esercizio era la seguente: sul file binario si memorizza la sequenza intero-booleano-intero-booleano- nello stesso ordine in cui questi elementi starebbero in un vettore; la funzione ricorsiva di visita prende come parametro l'indice dell'elemento da visitare, come per i vettori; dato questo indice pos, l'intero e il booleano stanno nel file binario in posizione pos*2*sizeof(int), e si possono quindi leggere facendo prima una fseek e poi due fread.
Testo
Scrivere una funzione che riceva come parametro una lista, e costruisca una nuova lista composta dai soli elementi pari della prima, nello stesso ordine in cui si trovano nella lista. Si vedano gli esempi qui sotto.
| Parametro | Lista ritornata |
|---|---|
| (1 3 5 8 9 10 2) | (8 10 2) |
| () | () |
| (2 4 2 6) | (2 4 2 6) |
| (1 9 3 5) | () |
| (2 1 1 1 2) | (2 2) |
Si noti che la lista di partenza non deve essere modificata: la funzione riceve come parametro una lista, e ne restituisce una nuova come valore di ritorno.
Valutazione per questo esercizio:
Driver e file di prova
Programma driver: 16set02-driver.c La soluzione va inserita dove appare il commento /* inserire qui la soluzione */, e deve avere il prototipo:
TipoLista SoloPari(TipoLista);
Il nome del file che contiene la lista che viene passata alla funzione va dato da linea di comando (da prompt dei comandi, si fa 16set02-driver nomefile, mentre dal TurboC si può impostare il nome del fil nel menu Run->Arguments). Alcuni possibili file di prova, con i valori che devono risultare, sono i seguenti:
| File lista | Risultato funzione |
|---|---|
| lista0.txt (lista vuota) | (lista vuota) |
| lista1.txt | 12 |
| lista2.txt | 4 4 2 |
| lista3.txt | 8 2 8 4 |
| lista4.txt | (lista vuota) |
| lista5.txt | 2 4 2 |
| lista6.txt | 0 2 8 2 |
Soluzione
Il primo livello di raffinamento dell'algoritmo indica soltanto che ogni elemento pari della lista va messo in una nuova lista.
per ogni elemento della vecchia lista
se e' pari
inseriscilo nella nuova lista
A questo punto, va precisato che la lista vecchia va scandita in ordine, e che gli elementi vanno inseriti nella nuova lista in ordine. Quindi, l'inserimeno va fatto in coda alla lista nuova.
nuova_lista=lista vuota
per ogni elemento della vecchia lista
se e' pari
inseriscilo in coda alla nuova lista
A questo punto, la traduzione in codice è ovvia, usando la funzione InserisciCodaLista che inserisce un elemento in coda a una lista:
TipoLista SoloPari(TipoLista l) {
TipoLista s;
s=NULL;
while(l!=NULL) {
if(l->val%2==0)
InserisciCodaLista(&s,l->val);
l=l->next;
}
return s;
}
Per completare la soluzione occorre anche riportare il testo della funzione InserisciCodaLista, che inserisce un elemento in coda a una lista. Si può anche usare la stessa funzione che è riportata nel resto del materiale didattico, e che viene copiata qui sotto.
void InserisciCodaLista(TipoLista *pl, int e) {
TipoLista t;
/* caso lista inizialmente vuota */
if(*pl==NULL) {
*pl=malloc(sizeof(struct NodoLista));
(*pl)->val=e;
(*pl)->next=NULL;
return;
}
/* caso lista con almeno un elemento */
t=*pl;
/* vado avanti fino alla fine della lista */
while(t->next!=NULL)
t=t->next;
/* qui t punta all'ultima struttura della lista: ne
creo una nuova e sposto il puntatore in avanti */
t->next=malloc(sizeof(struct NodoLista));
t=t->next;
/* metto i valori nell'ultima struttura */
t->val=e;
t->next=NULL;
}
Testo
Descrivere i due metodi di rappresentazione in memoria degli alberi n-ari (punteggio massimo per questo esercizio: 6 punti).
Soluzione
Vanno descritti i file binari, che sono spiegati nelle relative pagine delle dispense.
Testo
Si vogliono memorizzare i dati relativi agli articoli in vendita in un negozio usando un file.
I dati da memorizzare sono in particolare i seguenti: nel negozio sono presenti differenti tipi di prodotti, e ogni prodotto è caratterizzato da un codice (un numero intero). Il file deve contenere esclusivamente le seguenti informazioni: per ogni prodotto, va memorizzato il numero di articoli attualmente presenti nel negozio. Dal momento che anche questo è un intero, il file deve contenere, per ogni prodotto, il suo codice e il numero di articoli (non deve quindi contenere una descrizione a lettere del prodotto, o altri dati).
Dire quale tipo di file è migliore per rappresentare questi dati, tenendo presente che il numero di articoli viene aggiornato ogni volta che un prodotto viene venduto. Scrivere l'algoritmo e la funzione che aggiorna il file quando un articolo viene venduto (ossia il numero di articoli presenti per un certo prodotto va diminuito di uno).
Il punteggio massimo per questo esercizio sarà di 6 punti.
Soluzione
Il tipo di file viene deciso in base alle operazioni possibili e alla comodità di uso, mentre la dimensione del file è di solito un problema secondario. In particolare, i criteri di scelta sono:
In questo caso, abbiamo bisogno dei file binari per il semplice motivo che il dato che rappresenta il numero di articoli di un certo prodotto si trova (di solito) in mezzo al file, e quindi sono necessarie modifiche all'interno del file.
Mentre nei file di testo una modifica comporta la completa riscrittura del file, in quelli binari è sufficiente posizionarsi nel punto in cui si trova il dato da modificare e riscriverlo.
Nel nostro caso, si può quindi usare usare la seguente disposizione. Per ogni prodotto, si memorizzano due interi: il primo è il codice, il secondo il numero di articoli.
Per effettuare la modifica si procede nel seguente modo: si fa una scansione del file finchè non si trova il codice del prodotto. Si legge poi il numero di articoli presenti, si diminuisce di uno, e si scrive il nuovo numero. Da notare che il numero diminuito va scritto al posto del vecchio. Quindi, prima di riscriverlo, occorre posizionarsi indietro nel file.
leggi il file a coppie di interi
se il codice prodotto è quello da modificare
decrementa il numero prodotto
torna indietro nel file di sizeof(int)
scrivi il numero prodotto
Il codice (facoltativo) è quindi quello che segue:
while(1) {
res=fread(&codice, sizeof(int), 1, fd);
if(res!=1)
break;
res=fread(&numero, sizeof(int), 1, fd);
if(res!=1)
break;
if(codice=codice_da_cercare) {
numero++;
fseek(fd, -sizeof(int), SEEK_CUR);
fwrite(&numero, sizeof(int), 1, fd);
}
}
I punti fondamentali da dire per la soluzione di questo esercizio erano: si usano file binari perchè vanno modificati elementi in mezzo; per fare le modifiche occorre leggere il file fino a trovare l'elemento da modificare, tornare indietro con fseek e modificarlo.